
De plus en plus de personnes, et de plus en plus de développeurs, parlent de données structurées, et de Schema.org. Nous parlons et avons parlé de Schema pendant un certain temps chez Yoast et nous avons construit des tas de choses avec et par-dessus. Récemment, la proposition protocole de bloc standard a commencé à parler d’intégration avec Schema, et l’équipe principale de WordPress s’y intéresse également ; voir cette discussion sur Github.
Les métadonnées de Schema.org sont une version lisible et interprétable par une machine du contenu d’une page. Chez Yoast, nous sommes très fiers du balisage de schéma généré par Yoast SEO. La principale raison pour laquelle nous en sommes si fiers est que nous nous efforçons de faire en sorte que lorsqu’une machine le lit, elle l’interprète correctement. Pour ce faire, nous avons déterminé que Schema devrait toujours être un graphique interconnecté.
A quoi ressemble un bon graphique
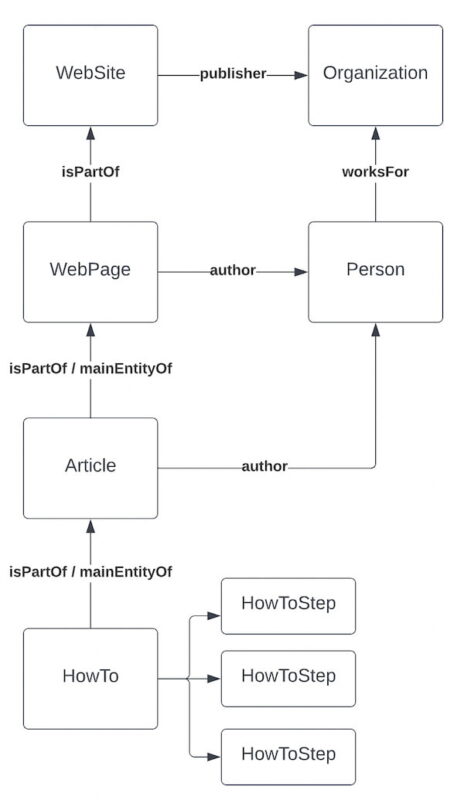
Disons que nous avons une page avec un article, et que cet article contient un HowTo. Nous supposerons que le HowTo est la « raison d’être » de l’article. Notre graphique Yoast SEO, une fois analysé, ressemblerait à ceci :
La Article et WebPage aurait un ou plusieurs auteurs, des dates de publication, des images, le site serait la propriété d’une organisation, etc. tonne de métadonnées dans notre schéma, ce qui est très utile pour les moteurs de recherche. Certaines des données sont au niveau de la page (comme la langue), certaines des données sont généralement au niveau du site (comme l’éditeur), et tout fonctionne bien parce que nous lions tout ensemble.
Dans de nombreuses implémentations de schéma, ces parties sont ne pas liés ensemble sous forme de graphique. Ils sont jetés en blocs séparés. Ainsi, au lieu de la belle hiérarchie ci-dessus, vous obtiendrez :
HowToArticleWebPageWebSite
Et dans le cas ci-dessus, que force en fait être bien. Je dis peut-être pour une raison. Et si le HowTo n’est en fait qu’une partie tangentielle de Article? Il y a des cas où cela devient encore plus critique. Laisse moi te donner un exemple.
Quand Schema devient destructeur
C’est malheureusement un cas que j’ai rencontré dans la vraie vie. Un site Web avait une page de produit pour un seul produit. En dessous de ce produit, cinq produits connexes, des choses couramment achetées ensemble, etc. sont répertoriés. Le composant utilisé pour afficher le schéma de sortie de ces produits connexes pour ces cinq produits. Il n’était pas lié au reste du schéma de la page. Donc tu as ça :
Product(produit principal)Product(produit associé 1)Product(produit connexe 2)Product(produit connexe 3)Product(produit connexe 4)Product(produit connexe 5)
Product schema est chargé d’obtenir pour un site les beaux extraits enrichis qui affichent le nombre d’étoiles, le prix et la disponibilité des produits dans les résultats de la recherche. Dans ce cas, les moteurs de recherche ne savaient pas quel produit choisir ; en fait, l’outil de test de résultats enrichi de Google ne vous donnera même pas de résultat. Lorsque vous regardez ce schéma hors du contexte de sa conception, il n’y a aucun moyen de savoir quel produit est le produit principal sur la page parce que le schéma n’était pas lié en un seul graphique. Le résultat est une perte d’extraits enrichis pour ces pages. Un changement directement attribuable à une perte de ventes.
Le réparer signifiait connecter les cinq en relation produits au produit principal avec isRelatedTo propriétés, en supprimant les Product une partie de leur production, puis en déclarant le principale produit comme le mainEntityOfPage. Le point ici est que ces blocs de produits devaient se comporter différemment en fonction de le contexte et leurs relations avec d’autres blocs sur (et des informations sur) la page. C’est le genre de compréhension dont vous avez besoin pour pouvoir créer une sortie de schéma fonctionnelle.
Les morceaux geek : comment nous lions le tout ensemble
Dans notre graphique, nous lions tous les éléments ensemble en spécifiant leur relation. Pour ce faire, nous référençons des « morceaux » de graphe comme nous les appelons, en @id. UN WebPage a un attribut isPartOffaisant référence à la WebSite pièce. Un Article a un isPartOf faisant référence à la WebPage. En fait, un Article par défaut a aussi un attribut mainEntityOfPage qui fait référence à WebPagese déclarant comme entité principale.
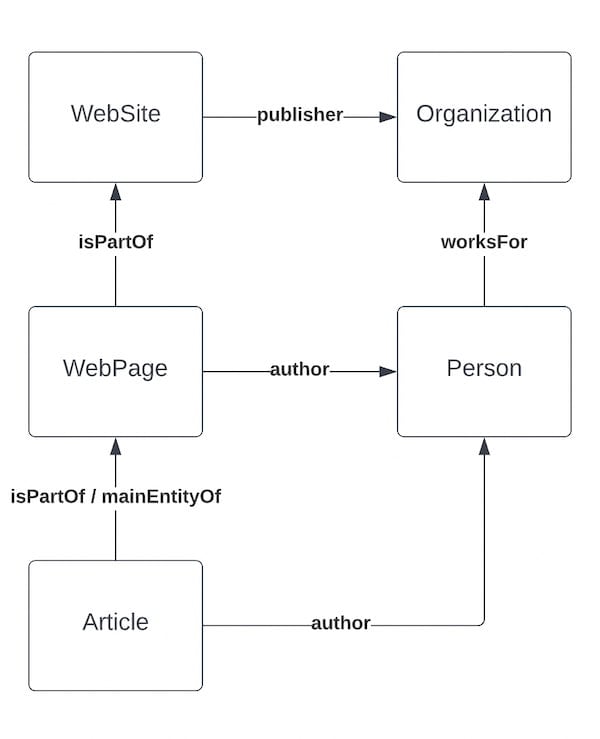
Si vous ajoutez un HowTo à ce mélange, il se déclarerait le mainEntityOfPage de la Article. Si la HowTo fait partie d’une page qui ne s’affiche pas Article schéma, il ferait la même chose mais s’attacherait automatiquement en tant que mainEntityOfPage de la WebPage. De cette façon, un moteur de recherche peut analyser le graphique et voir exactement que se passe-t-il. Cela signifie que chaque bloc doit être conscient de son contexte lorsque son schéma est rendu.
Donc : les blocs et le schéma ne sont pas une seule et même chose
Alors que les blocs du nouvel éditeur WordPress sont génial pour une utilisation avec Schema, ils nécessitent un niveau d’analyse supplémentaire et une couche de logique métier être lié au reste de la page. Malheureusement, ce n’est pas aussi simple que de sortir le schéma de chaque bloc et de le laisser là. L’idée actuellement discutée sur le noyau WordPress GitHub, de lier Schema à Patterns, est, à mon avis, un peu trop… simpliste. Je ne dis pas que cela ne peut pas être fait, mais cela nécessite plus de travail. Il en va de même pour les discussions autour du Block Protocol.
Si vous souhaitez implémenter Schema, vous devez être disposé et capable de déterminer tout le contexte d’une page. Cette logique commerciale est complexe, interconnectée et en constante évolution à mesure que Google et d’autres consommateurs modifient et font évoluer leurs normes. Cette logique ne peut pas vivre dans chaque bloc individuel, dans chaque morceau individuel ; il a besoin d’un « cerveau » qui comprend toutes les pièces mobiles et peut décrire un graphique cohérent de toutes ces pièces mobiles.
Nous sommes très fiers de ce que Yoast SEO fait dans ce domaine, et nous proposons une API Schema qui permet à d’autres développeurs de s’y associer et d’ajouter leurs propres implémentations. Nous avons également écrit un plein Spécification du schéma de la façon dont notre sortie fonctionne et pourquoi. Sans ce « cerveau », une approche par blocs aura du mal à sans encombre décrire une page.
Joost de Valk est le fondateur de Yoast. Après avoir vendu Yoast, il a cessé d’être actif à temps plein et agit maintenant en tant que conseiller de l’entreprise. C’est un entrepreneur Internet qui, avec sa femme Marieke, investit activement et conseille plusieurs startups. Son expertise principale est le développement de logiciels open source et le marketing numérique.
