

le robots.txt Le fichier est l’un des principaux moyens de dire à un moteur de recherche où il peut et ne peut pas aller sur votre site Web. Tous les principaux moteurs de recherche prennent en charge les fonctionnalités de base qu'il offre, mais certains d'entre eux répondent à des règles supplémentaires qui peuvent également s'avérer utiles. Ce guide couvre toutes les façons d’utiliser robots.txt sur votre site Web, mais, même si cela semble simple, toutes les erreurs que vous faites dans votre robots.txt peut nuire gravement à votre site. Assurez-vous donc de lire et de comprendre l'ensemble de cet article avant de plonger.
Qu'est ce qu'un robots.txt fichier?
Un fichier robots.txt est un fichier texte lu par des robots de recherche et respectant une syntaxe stricte. Ces araignées sont également appelées robots – d'où leur nom – et la syntaxe du fichier est stricte simplement parce qu'il doit être lisible par ordinateur. Cela signifie qu’il n’ya pas de marge d’erreur possible ici: quelque chose vaut 1 ou 0.
Aussi appelé «Protocole d’exclusion des robots», le robots.txt Le fichier est le résultat d'un consensus parmi les premiers développeurs d'araignées de moteurs de recherche. Ce n’est pas une norme officielle définie par un organisme de normalisation, mais tous les principaux moteurs de recherche y adhèrent.
Que fait le robots.txt fichier faire?
Les moteurs de recherche indexent le Web en parcourant les pages, en suivant les liens pour aller du site A au site B, en passant par le site C, etc. Avant les araignées des moteurs de recherche tout page sur un domaine qu’il n’a jamais rencontré auparavant, il ouvrira le robots.txt fichier, qui indique au moteur de recherche quelles URL sur ce site il est autorisé à indexer.
Les moteurs de recherche mettent généralement en cache le contenu de la robots.txt, mais l’actualisera généralement plusieurs fois par jour, de sorte que les modifications seront reflétées assez rapidement.
Où devrais-je mettre mon robots.txt fichier?
le robots.txt Le fichier doit toujours être à la racine de votre domaine. Donc, si votre domaine est www.example.com, vous devriez le trouver à https://www.example.com/robots.txt.
Il est également très important que votre robots.txt le fichier s'appelle réellement robots.txt. Le nom est sensible à la casse, alors ne vous trompez pas ou cela ne fonctionnera tout simplement pas.
Avantages et inconvénients de l'utilisation robots.txt
Pro: gestion du budget d'analyse
Il est généralement admis qu'une araignée de recherche arrive sur un site Web avec une «indemnité» prédéterminée pour le nombre de pages explorées (ou la quantité de ressources / temps dépensée, en fonction de l'autorité / de la taille / de la réputation du site), et les référenceurs appellent cela le budget d'analyse. Cela signifie que si vous bloquez des sections de votre site à partir de l'araignée du moteur de recherche, vous pouvez autoriser l'utilisation de votre budget d'analyse pour d'autres sections.
Il peut parfois être très bénéfique d'empêcher les moteurs de recherche d'explorer des sections problématiques de votre site, en particulier sur les sites sur lesquels beaucoup de nettoyage SEO doit être effectué. Une fois que vous avez rangé les choses, vous pouvez les laisser rentrer.
Une note sur le blocage des paramètres de requête
Le budget d’analyse est particulièrement important lorsque votre site utilise de nombreux paramètres de chaîne de requête pour filtrer et trier. Disons que vous avez 10 paramètres de requête différents, chacun avec des valeurs différentes pouvant être utilisées dans n’importe quelle combinaison. Cela conduit à des centaines, voire des milliers d'URL possibles. En bloquant l’exploration de tous les paramètres de requête, vous vous assurez que le moteur de recherche ne traite que les URL principales de votre site et n’entre pas dans le piège énorme que vous auriez autrement créé.
Cette ligne bloque toutes les URL sur votre site contenant une chaîne de requête:
Interdit: / *? *
Con: ne pas supprimer une page des résultats de recherche
Même si vous pouvez utiliser le robots.txt fichier pour dire à une araignée où elle ne peut pas aller sur votre site, vous ne peux pas utilisez-le pour indiquer à un moteur de recherche quelles URL ne doivent pas apparaître dans les résultats de la recherche – en d’autres termes, le bloquer ne l’empêchera pas de l’indexer. Si le moteur de recherche trouve suffisamment de liens vers cette URL, il l’incluera, mais il ne saura tout simplement pas ce qui se trouve sur cette page. Donc, votre résultat ressemblera à ceci:

Si vous souhaitez empêcher de manière fiable l’affichage d’une page dans les résultats de la recherche, vous devez utiliser un méta-robot. noindex étiquette. Cela signifie que, pour trouver le noindex tag, le moteur de recherche doit pouvoir accéder à cette page, donc ne pas bloquer avec robots.txt.
Con: ne pas diffuser la valeur du lien
Si un moteur de recherche ne peut pas explorer une page, il ne peut pas répartir la valeur du lien sur les liens de cette page. Lorsqu'une page est bloquée avec robots.txt, c’est une impasse. Toute valeur de lien qui aurait pu circuler vers (et à travers) cette page est perdue.
robots.txt syntaxe
UNE robots.txt Le fichier consiste en un ou plusieurs blocs de directives, chacun commençant par une ligne d'agent utilisateur. Le « user-agent » est le nom de l'araignée spécifique qu'il adresse. Vous pouvez avoir un bloc pour tous les moteurs de recherche, en utilisant un caractère générique pour l'agent utilisateur ou des blocs spécifiques pour des moteurs de recherche spécifiques. Un moteur de recherche choisira toujours le bloc qui correspond le mieux à son nom.
Ces blocs ressemblent à ceci (n’ayez pas peur, nous expliquerons ci-dessous):
Agent utilisateur: *
Interdit: /Agent utilisateur: Googlebot
Refuser:Agent utilisateur: bingbot
Interdit: / pas pour bing /
Des directives comme Permettre et Refuser ne doit pas être sensible à la casse, c’est donc à vous de choisir si vous les écrivez en minuscule ou en majuscule. Les valeurs sont cas sensible cependant, /photo/ n'est pas la même chose que /Photo/. Nous aimons capitaliser les directives car cela facilite la lecture du fichier (pour les humains).
le Agent utilisateur directif
Le premier bit de chaque bloc de directives est l'agent utilisateur, qui identifie un spider spécifique. Le champ agent utilisateur est mis en correspondance avec l'agent utilisateur de cette araignée spécifique (généralement plus long). Ainsi, par exemple, l'araignée la plus courante de Google possède l'agent utilisateur suivant:
Mozilla / 5.0 (compatible; Googlebot / 2.1; + http: //www.google.com/bot.html)
Donc, si vous voulez dire à cette araignée quoi faire, un relativement simple Agent utilisateur: Googlebot La ligne fera l'affaire.
La plupart des moteurs de recherche ont plusieurs araignées. Ils utiliseront une araignée spécifique pour leur index normal, leurs programmes de publicité, leurs images, leurs vidéos, etc.
Les moteurs de recherche choisiront toujours le bloc de directives le plus spécifique qu'ils puissent trouver. Disons que vous avez 3 ensembles de directives: une pour *, un pour Googlebot et un pour Googlebot-News. Si un bot vient par dont l'utilisateur-agent est Googlebot-Video, il suivrait le Restrictions de Googlebot. Un bot avec l'agent utilisateur Googlebot-News utiliserait le plus spécifique Googlebot-News directives.
Les agents utilisateurs les plus courants pour les spiders des moteurs de recherche
Voici une liste des agents utilisateurs que vous pouvez utiliser dans votre robots.txt fichier pour correspondre aux moteurs de recherche les plus couramment utilisés:
| Moteur de recherche | Champ | Agent utilisateur |
|---|---|---|
| Baidu | Général | baiduspider |
| Baidu | Images | baiduspider-image |
| Baidu | Mobile | baiduspider-mobile |
| Baidu | Nouvelles | baiduspider-news |
| Baidu | Vidéo | baiduspider-video |
| Bing | Général | bingbot |
| Bing | Général | msnbot |
| Bing | Images et vidéo | msnbot-media |
| Bing | Les publicités | adidxbot |
| Général | Googlebot |
|
| Images | Googlebot-Image |
|
| Mobile | Googlebot-Mobile |
|
| Nouvelles | Googlebot-News |
|
| Vidéo | Googlebot-Video |
|
| AdSense | Mediapartners-Google |
|
| AdWords | AdsBot-Google |
|
| Yahoo! | Général | slurp |
| Yandex | Général | Yandex |
le Refuser directif
La deuxième ligne de tout bloc de directives est la suivante: Refuser ligne. Vous pouvez avoir une ou plusieurs de ces lignes, spécifiant les parties du site auxquelles l'araignée spécifiée ne peut pas accéder. Un vide Refuser La ligne signifie que vous ne refusez rien, donc cela signifie qu’une araignée peut accéder à toutes les sections de votre site.
L’exemple ci-dessous bloquerait tous les moteurs de recherche qui «écoutent» robots.txt de l'exploration de votre site.
Agent utilisateur: *
Interdit: /
L’exemple ci-dessous serait, avec un seul caractère de moins, permettre tous les moteurs de recherche pour explorer l'ensemble de votre site.
Agent utilisateur: *
Refuser:
L’exemple ci-dessous empêcherait Google d’explorer le Photo répertoire sur votre site – et tout ce qu’il contient.
Agent utilisateur: googlebot
Interdit: / Photo
Cela signifie que tous les sous-répertoires du /Photo répertoire ne serait pas non plus spidered. Il serait ne pas empêcher Google d'explorer le /photo répertoire, car ces lignes sont sensibles à la casse.
Ce serait également bloquer l'accès de Google aux URL contenant /Photo, tel que /La photographie/.
Comment utiliser des caractères génériques / expressions régulières
« Officiellement », le robots.txt Standard ne prend pas en charge les expressions régulières ou les caractères génériques. Cependant, tous les principaux moteurs de recherche le comprennent. Cela signifie que vous pouvez utiliser de telles lignes pour bloquer des groupes de fichiers:
Interdit: /*.php
Interdit: /copyrighted-images/*.jpg
Dans l'exemple ci-dessus, * est étendu au nom de fichier correspondant. Notez que le reste de la ligne est toujours sensible à la casse. La deuxième ligne ci-dessus ne bloquera donc pas un fichier appelé /copyrighted-images/example.JPG d'être rampé.
Certains moteurs de recherche, tels que Google, autorisent des expressions régulières plus complexes, mais sachez que certains moteurs de recherche pourraient ne pas comprendre cette logique. La fonctionnalité la plus utile à ajouter est la $, qui indique la fin d'une URL. Dans l'exemple suivant, vous pouvez voir ce que cela fait:
Interdit: /*.php$
Ça signifie /index.php ne peut pas être indexé, mais /index.php?p=1 pourrait être. Bien sûr, cela n’est utile que dans des circonstances très spécifiques et également très dangereux: il est facile de débloquer des choses que vous ne vouliez pas réellement débloquer.
Non standard robots.txt directives d'exploration
Aussi bien que Refuser et Agent utilisateur directives, vous pouvez utiliser deux autres directives d’exploration. Ces directives ne sont pas prises en charge par tous les robots d'exploration des moteurs de recherche. Par conséquent, assurez-vous de connaître leurs limites.
le Permettre directif
Bien que ne figurant pas dans la «spécification» initiale, il a été question très tôt d’une permettre directif. La plupart des moteurs de recherche semblent le comprendre, et cela permet des directives simples et très lisibles comme ceci:
Interdit: / wp-admin /
Autoriser: /wp-admin/admin-ajax.php
Le seul autre moyen de parvenir au même résultat sans un permettre directive aurait été spécifiquement refuser chaque fichier dans le wp-admin dossier.
le hôte directif
Soutenue par Yandex (et non par Google, malgré ce que disent certains articles), cette directive vous permet de décider si vous souhaitez que le moteur de recherche affiche exemple.com ou www.example.com. Il suffit de le spécifier comme ceci:
hôte: exemple.com
Mais parce que seul Yandex soutient le hôte directive, nous ne vous conseillerions pas de vous y fier, d’autant plus que cela ne vous autorise pas non plus à définir un schéma (http ou https). Une meilleure solution qui fonctionne pour tous les moteurs de recherche serait de rediriger les noms d’hôte que vous ne pas vouloir dans l'index de la version que vous faire vouloir. Dans notre cas, nous redirigeons www.yoast.com vers yoast.com.
le délai d'analyse directif
Yahoo !, Bing et Yandex peuvent parfois avoir faim, mais heureusement, ils répondent tous à la délai d'analyse directive, ce qui les ralentit. Et bien que ces moteurs de recherche aient des manières légèrement différentes de lire la directive, le résultat final est fondamentalement le même.
Une ligne comme celle ci-dessous indiquerait à Yahoo! et Bing attend 10 secondes après une analyse, tandis que Yandex n’accédera à votre site que toutes les 10 secondes. C’est une différence sémantique, mais il est toujours intéressant de savoir. Voici l'exemple délai d'analyse ligne:
délai d'exploration: 10
Faites attention lorsque vous utilisez le délai d'analyse directif. En définissant un délai d'analyse de 10 secondes, vous n'autorisez que ces moteurs de recherche à accéder à 8 640 pages par jour. Cela peut sembler suffisant pour un petit site, mais sur de grands sites, il n’est pas très nombreux. D’autre part, si ces moteurs de recherche n’entraînent quasiment aucun trafic, c’est un bon moyen d’économiser de la bande passante.
le plan du site directive pour les sitemaps XML
En utilisant le plan du site directive, vous pouvez indiquer aux moteurs de recherche – en particulier Bing, Yandex et Google – où trouver votre sitemap XML. Vous pouvez bien sûr également soumettre vos plans Sitemap XML à chaque moteur de recherche à l'aide de leurs solutions respectives d'outils pour les webmasters, ce que nous vous recommandons vivement, car les programmes d'outils pour les webmasters des moteurs de recherche vous donneront de nombreuses informations précieuses sur votre site. Si vous ne voulez pas faire cela, ajoutez un plan du site ligne à votre robots.txt est une bonne alternative rapide.
Validez votre robots.txt
Il existe différents outils qui peuvent vous aider à valider votre robots.txt, mais quand il s’agit de valider des directives d’analyse, nous préférons toujours aller à la source. Google a un robots.txt dans la console de recherche Google (dans le menu « Ancienne version ») et nous vous recommandons vivement de l'utiliser:
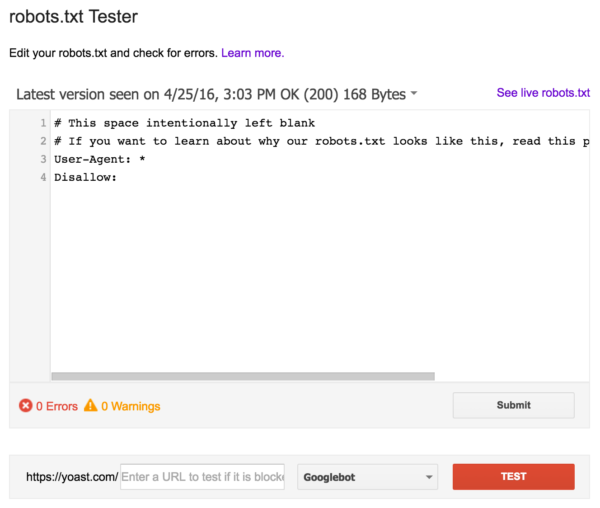
Assurez-vous de bien tester vos modifications avant de les mettre en ligne! Vous ne seriez pas le premier à utiliser accidentellement robots.txt pour bloquer l'ensemble de votre site et vous glisser dans l'oubli des moteurs de recherche!
Lire la suite: WordPress SEO: Le guide ultime pour un classement plus élevé des sites WordPress »