
Google’s Bard est basé sur le modèle de langage LaMDA, formé sur des ensembles de données basés sur du contenu Internet appelé Infiniset dont on sait très peu d’où proviennent les données et comment elles les ont obtenues.
Le document de recherche LaMDA 2022 répertorie les pourcentages de différents types de données utilisées pour former LaMDA, mais seulement 12,5 % proviennent d’un ensemble de données publiques de contenu exploré sur le Web et 12,5 % supplémentaires proviennent de Wikipedia.
Google est délibérément vague quant à l’origine du reste des données récupérées, mais il existe des indices sur les sites contenus dans ces ensembles de données.
Ensemble de données Infiniset de Google
Google Bard est basé sur un modèle de langage appelé LaMDA, qui est un acronyme pour Modèle de langage pour les applications de dialogue.
LaMDA a été formé sur un jeu de données appelé Infiniset.
Infiniset est un mélange de contenu Internet qui a été délibérément choisi pour améliorer la capacité du modèle à dialoguer.
Le document de recherche LaMDA (PDF) explique pourquoi ils ont choisi cette composition de contenu :
« … cette composition a été choisie pour obtenir des performances plus robustes sur les tâches de dialogue … tout en conservant sa capacité à effectuer d’autres tâches comme la génération de code.
Comme travaux futurs, nous pouvons étudier comment le choix de cette composition peut affecter la qualité de certaines des autres tâches NLP effectuées par le modèle.
Le document de recherche fait référence à dialogue et dialoguesqui est l’orthographe des mots utilisés dans ce contexte, dans le domaine de l’informatique.
Au total, LaMDA a été pré-formé sur 1,56 trillion de mots de «données de dialogue public et texte Web.”
L’ensemble de données est composé du mélange suivant :
- 12,5 % de données basées sur C4
- 12,5 % Wikipédia en anglais
- 12,5 % codent des documents provenant de sites Web de questions-réponses sur la programmation, de didacticiels et autres
- 6,25 % de documents Web en anglais
- 6,25 % de documents Web dans une autre langue que l’anglais
- 50 % de données de dialogue provenant de forums publics
Les deux premières parties d’Infiniset (C4 et Wikipedia) sont constituées de données connues.
Le jeu de données C4, qui sera exploré sous peu, est une version spécialement filtrée du jeu de données Common Crawl.
Seulement 25 % des données proviennent d’une source nommée (le C4 ensemble de données et Wikipédia).
Le reste des données qui constituent l’essentiel de l’ensemble de données Infiniset, 75 %, sont constitués de mots extraits d’Internet.
Le document de recherche ne dit pas comment les données ont été obtenues à partir de sites Web, sur quels sites Web elles ont été obtenues ou tout autre détail sur le contenu récupéré.
Google n’utilise que des descriptions générales telles que « Documents Web non anglais ».
Le mot « obscur » signifie quand quelque chose n’est pas expliqué et est en grande partie caché.
Obscur est le meilleur mot pour décrire les 75 % de données que Google a utilisées pour former LaMDA.
Il y a des indices qui peut donner une idée générale de quels sites sont contenus dans les 75 % de contenu Web, mais nous ne pouvons pas le savoir avec certitude.
Jeu de données C4
C4 est un ensemble de données développé par Google en 2020. C4 signifie « Corpus rampant propre et colossal.”
Cet ensemble de données est basé sur les données Common Crawl, qui est un ensemble de données open source.
À propos de Common Crawl
Exploration commune est une organisation à but non lucratif enregistrée qui explore Internet sur une base mensuelle pour créer des ensembles de données gratuits que tout le monde peut utiliser.
L’organisation Common Crawl est actuellement dirigée par des personnes qui ont travaillé pour la Wikimedia Foundation, d’anciens Googleurs, un fondateur de Blekko, et comptent comme conseillers des personnes comme Peter Norvig, directeur de la recherche chez Google et Danny Sullivan (également de Google).
Comment C4 est développé à partir de Common Crawl
Les données brutes de Common Crawl sont nettoyées en supprimant des éléments tels que le contenu fin, les mots obscènes, le lorem ipsum, les menus de navigation, la déduplication, etc. afin de limiter l’ensemble de données au contenu principal.
Le but du filtrage des données inutiles était de supprimer le charabia et de conserver des exemples d’anglais naturel.
Voici ce qu’ont écrit les chercheurs qui ont créé C4 :
« Pour assembler notre ensemble de données de base, nous avons téléchargé le texte extrait du Web d’avril 2019 et appliqué le filtrage susmentionné.
Cela produit une collection de texte qui est non seulement plus grande que la plupart des ensembles de données utilisés pour la pré-formation (environ 750 Go), mais qui comprend également un texte anglais raisonnablement propre et naturel.
Nous appelons cet ensemble de données le « Colossal Clean Crawled Corpus » (ou C4 en abrégé) et le publions dans le cadre des ensembles de données TensorFlow… »
Il existe également d’autres versions non filtrées de C4.
Le document de recherche qui décrit l’ensemble de données C4 est intitulé, Explorer les limites de l’apprentissage par transfert avec un transformateur texte-texte unifié (PDF).
Un autre document de recherche de 2021, (Documenter de grands corpus de textes Web : une étude de cas sur le corpus colossal propre et exploré – PDF) a examiné la composition des sites inclus dans l’ensemble de données C4.
Fait intéressant, le deuxième document de recherche a découvert des anomalies dans l’ensemble de données C4 d’origine qui ont entraîné la suppression de pages Web alignées sur les hispaniques et les afro-américains.
Les pages Web alignées hispaniques ont été supprimées par le filtre de la liste de blocage (gros mots, etc.) à raison de 32 % des pages.
Les pages Web alignées afro-américaines ont été supprimées au taux de 42 %.
Ces lacunes ont probablement été corrigées…
Une autre découverte était que 51,3% de l’ensemble de données C4 consistait en des pages Web hébergées aux États-Unis.
Enfin, l’analyse de 2021 de l’ensemble de données C4 original reconnaît que l’ensemble de données ne représente qu’une fraction de l’Internet total.
L’analyse précise :
« Notre analyse montre que si cet ensemble de données représente une fraction importante d’une partie de l’Internet public, il n’est en aucun cas représentatif du monde anglophone et s’étend sur un large éventail d’années.
Lors de la création d’un ensemble de données à partir d’un grattage du Web, le signalement des domaines à partir desquels le texte est gratté fait partie intégrante de la compréhension de l’ensemble de données ; le processus de collecte de données peut conduire à une répartition des domaines Internet très différente de ce à quoi on pourrait s’attendre.
Les statistiques suivantes sur l’ensemble de données C4 proviennent du deuxième document de recherche lié ci-dessus.
Les 25 meilleurs sites Web (par nombre de jetons) dans C4 sont :
- brevets.google.com
- fr.wikipedia.org
- fr.m.wikipedia.org
- www.nytimes.com
- www.latimes.com
- www.theguardian.com
- journaux.plos.org
- www.forbes.com
- www.huffpost.com
- brevets.com
- www.scribd.com
- www.washingtonpost.com
- www.fou.com
- ipfs.io
- www.frontiersin.org
- www.businessinsider.com
- www.chicagotribune.com
- www.booking.com
- www.theatlantic.com
- lien.springer.com
- www.aljazeera.com
- www.kickstarter.com
- caselaw.findlaw.com
- www.ncbi.nlm.nih.gov
- www.npr.org
Voici les 25 domaines de premier niveau les plus représentés dans l’ensemble de données C4 :
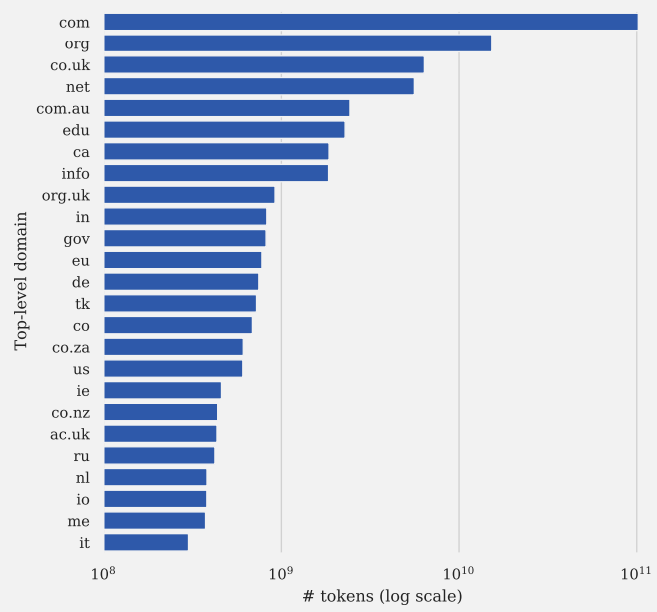 Capture d’écran de Documenter de grands corpus de textes Web : une étude de cas sur le corpus colossal propre et exploré
Capture d’écran de Documenter de grands corpus de textes Web : une étude de cas sur le corpus colossal propre et exploréSi vous souhaitez en savoir plus sur l’ensemble de données C4, je vous recommande de lire Documenter de grands corpus de textes Web : une étude de cas sur le corpus colossal propre et exploré (PDF) ainsi que le document de recherche original de 2020 (PDF) pour lequel C4 a été créé.
Que pourraient être les données des dialogues des forums publics ?
50% des données d’entraînement proviennent de « dialogues données de forums publics.”
C’est tout ce que dit le document de recherche LaMDA de Google sur ces données de formation.
Si l’on devait deviner, Reddit et d’autres communautés de premier plan comme StackOverflow sont des valeurs sûres.
Reddit est utilisé dans de nombreux ensembles de données importants tels que ceux développé par OpenAI appelé WebText2 (PDF)une approximation open-source de WebText2 appelée OpenWebText2 et propre à Google WebText-like (PDF) ensemble de données à partir de 2020.
Google a également publié les détails d’un autre ensemble de données de sites de dialogue public un mois avant la publication de l’article de LaMDA.
Cet ensemble de données qui contient des sites de dialogue publics est appelé MassiveWeb.
Nous ne supposons pas que l’ensemble de données MassiveWeb a été utilisé pour former LaMDA.
Mais il contient un bon exemple de ce que Google a choisi pour un autre modèle de langage axé sur le dialogue.
MassiveWeb a été créé par DeepMind, qui appartient à Google.
Il a été conçu pour être utilisé par un grand modèle de langage appelé Gopher (lien vers le PDF du document de recherche).
MassiveWeb utilise des sources Web de dialogue qui vont au-delà de Reddit afin d’éviter de créer un biais envers les données influencées par Reddit.
Il utilise toujours Reddit. Mais il contient également des données extraites de nombreux autres sites.
Les sites de dialogue public inclus dans MassiveWeb sont :
- Quora
- Youtube
- Moyen
- StackOverflow
Encore une fois, cela ne signifie pas que LaMDA a été formé avec les sites ci-dessus.
Il est simplement destiné à montrer ce que Google aurait pu utiliser, en montrant un ensemble de données sur lequel Google travaillait à peu près au même moment que LaMDA, celui qui contient des sites de type forum.
Les 37,5 % restants
Le dernier groupe de sources de données sont :
- 12,5 % codent des documents provenant de sites liés à la programmation tels que des sites de questions-réponses, des tutoriels, etc ;
- 12,5 % Wikipédia (anglais)
- 6,25 % de documents Web en anglais
- 6,25 % Documents Web non anglophones.
Google ne précise pas quels sites sont dans le Sites de questions et réponses sur la programmation catégorie qui représente 12,5 % de l’ensemble de données sur lequel LaMDA s’est entraîné.
Nous ne pouvons donc que spéculer.
Stack Overflow et Reddit semblent être des choix évidents, d’autant plus qu’ils ont été inclus dans l’ensemble de données MassiveWeb.
Quoi « tutoriels” les sites ont été explorés ? Nous ne pouvons que spéculer sur ce que pourraient être ces sites de « tutoriels ».
Cela laisse les trois dernières catégories de contenu, dont deux sont extrêmement vagues.
Wikipédia en anglais n’a pas besoin de discussion, nous connaissons tous Wikipédia.
Mais les deux suivants ne sont pas expliqués :
Anglais et non anglais les pages Web en langues sont une description générale de 13% des sites inclus dans la base de données.
Ce sont toutes les informations que Google donne sur cette partie des données d’entraînement.
Google devrait-il être transparent sur les ensembles de données utilisés pour Bard ?
Certains éditeurs se sentent mal à l’aise que leurs sites soient utilisés pour former des systèmes d’IA car, à leur avis, ces systèmes pourraient à l’avenir rendre leurs sites Web obsolètes et disparaître.
Reste à savoir si cela est vrai ou non, mais c’est une véritable préoccupation exprimée par les éditeurs et les membres de la communauté du marketing de recherche.
Google est désespérément vague sur les sites Web utilisés pour former LaMDA ainsi que sur la technologie utilisée pour récupérer les données sur les sites Web.
Comme on l’a vu dans l’analyse de l’ensemble de données C4, la méthodologie de choix du contenu du site Web à utiliser pour la formation de grands modèles linguistiques peut affecter la qualité du modèle linguistique en excluant certaines populations.
Google devrait-il être plus transparent sur les sites utilisés pour former son IA ou au moins publier un rapport de transparence facile à trouver sur les données qui ont été utilisées ?
Image sélectionnée par Shutterstock/Asier Romero