
Il y a beaucoup à savoir sur l'intention de recherche, en utilisant l'apprentissage en profondeur pour déduire l'intention de recherche en classant le texte et en décomposant les titres SERP en utilisant des techniques de traitement du langage naturel (PNLP), au regroupement basé sur la pertinence sémantique, avec les avantages expliqués.
Non seulement nous connaissons les avantages du déchiffrement de l'intention de recherche, mais nous avons également un certain nombre de techniques à notre disposition pour l'échelle et l'automatisation.
Alors, pourquoi avons-nous besoin d'un autre article sur l'automatisation de l'intention de recherche?
L'intention de recherche est de plus en plus importante maintenant que la recherche sur l'IA est arrivée.
Alors que plus se trouvait généralement dans l'ère de la recherche des 10 liens bleues, l'inverse est vrai avec la technologie de recherche d'IA, car ces plateformes cherchent généralement à minimiser les coûts informatiques (par flop) afin de fournir le service.
Les serps contiennent toujours les meilleures idées pour l'intention de recherche
Jusqu'à présent, les techniques impliquent de faire votre propre IA, c'est-à-dire d'obtenir toutes les copies à partir de titres du contenu de classement pour un mot-clé donné, puis de l'alimenter dans un modèle de réseau neuronal (que vous devez ensuite construire et tester) ou utiliser PNLP pour cluster des mots clés.
Et si vous n'avez pas le temps ou les connaissances pour construire votre propre IA ou invoquer l'API d'IA ouvert?
Bien que la similitude des cosinus ait été présentée comme la réponse pour aider les professionnels du référencement à naviguer dans la démarcation des sujets pour la taxonomie et les structures de site, je maintiens toujours que le clustering de recherche par les résultats du SERP est une méthode bien supérieure.
En effet, l'IA est très désireuse de fonder ses résultats sur les SERP et pour une bonne raison – il est modélisé sur les comportements des utilisateurs.
Il existe une autre façon qui utilise la propre IA de Google pour faire le travail pour vous, sans avoir à gratter tout le contenu SERPS et à créer un modèle d'IA.
Supposons que Google classe les URL du site par la probabilité que le contenu satisfaisant la requête utilisateur par ordre décroissant. Il s'ensuit que si l'intention de deux mots clés est la même, les SERP sont probablement similaires.
Pendant des années, de nombreux professionnels du référencement ont comparé les résultats du SERP pour que les mots clés déduisent l'intention de recherche partagée (ou partagée) pour rester au-dessus des mises à jour de base, donc ce n'est pas nouveau.
La valeur ajoutée ici est l'automatisation et la mise à l'échelle de cette comparaison, offrant à la fois une vitesse et une plus grande précision.
Comment regrouper les mots clés en recherchant l'intention à l'échelle en utilisant Python (avec code)
En supposant que vous avez vos résultats SERPS dans un téléchargement CSV, importons-le dans votre ordinateur portable Python.
1. Importez la liste dans votre cahier Python
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
Vous trouverez ci-dessous le fichier SERPS désormais importé dans un Pandas DataFrame.
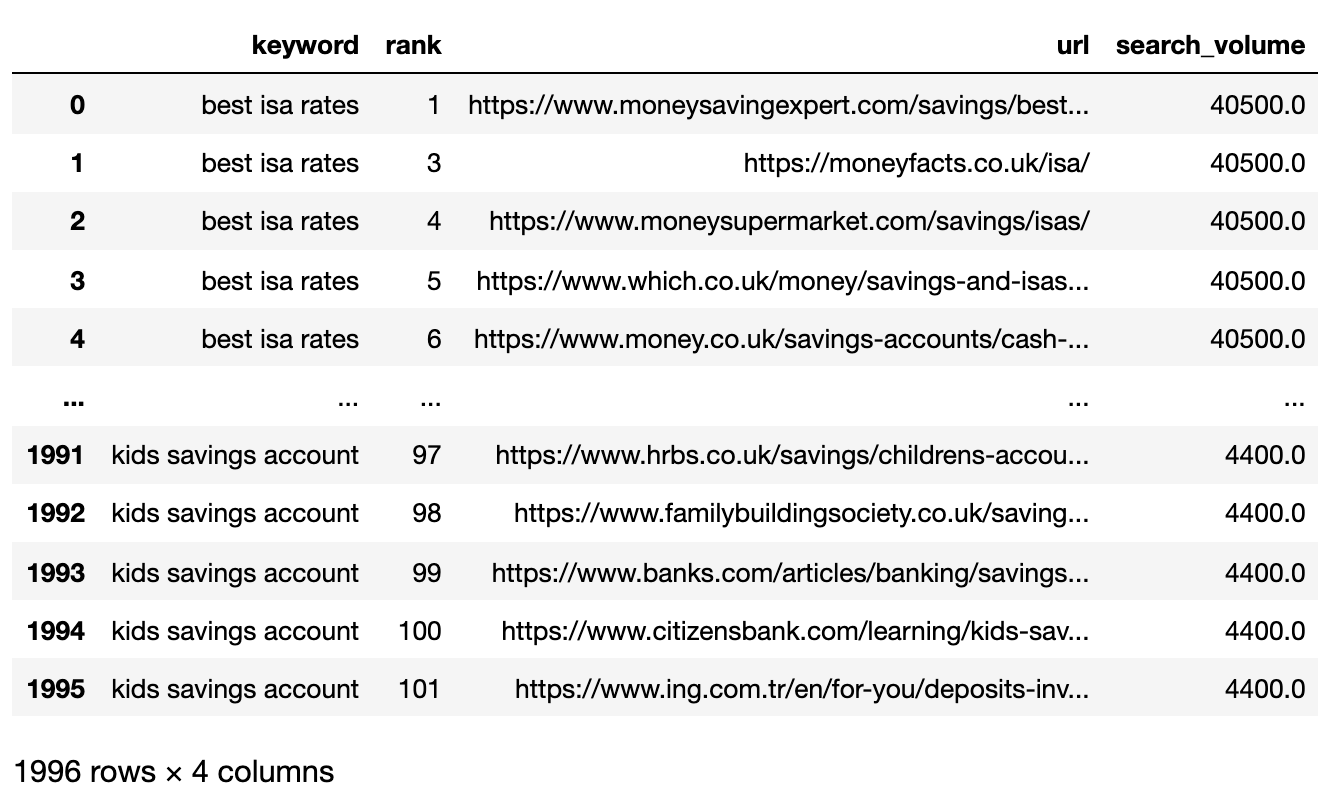 Image de l'auteur, avril 2025
Image de l'auteur, avril 20252. Filtre les données de la page 1
Nous voulons comparer les résultats de la page 1 de chaque Serp entre les mots clés.
Nous allons diviser le DataFrame en mini mot clé DataFrames pour exécuter la fonction de filtrage avant de recombiner en un seulframe de données, car nous voulons filtrer au niveau du mot-clé:
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls]
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Combine
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with initial data frame
filtered_serps_df = pd.concat([filtered_serps],axis=0)
del filtered_serps_df['keyword']
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df['level_1']
filtered_serps_df
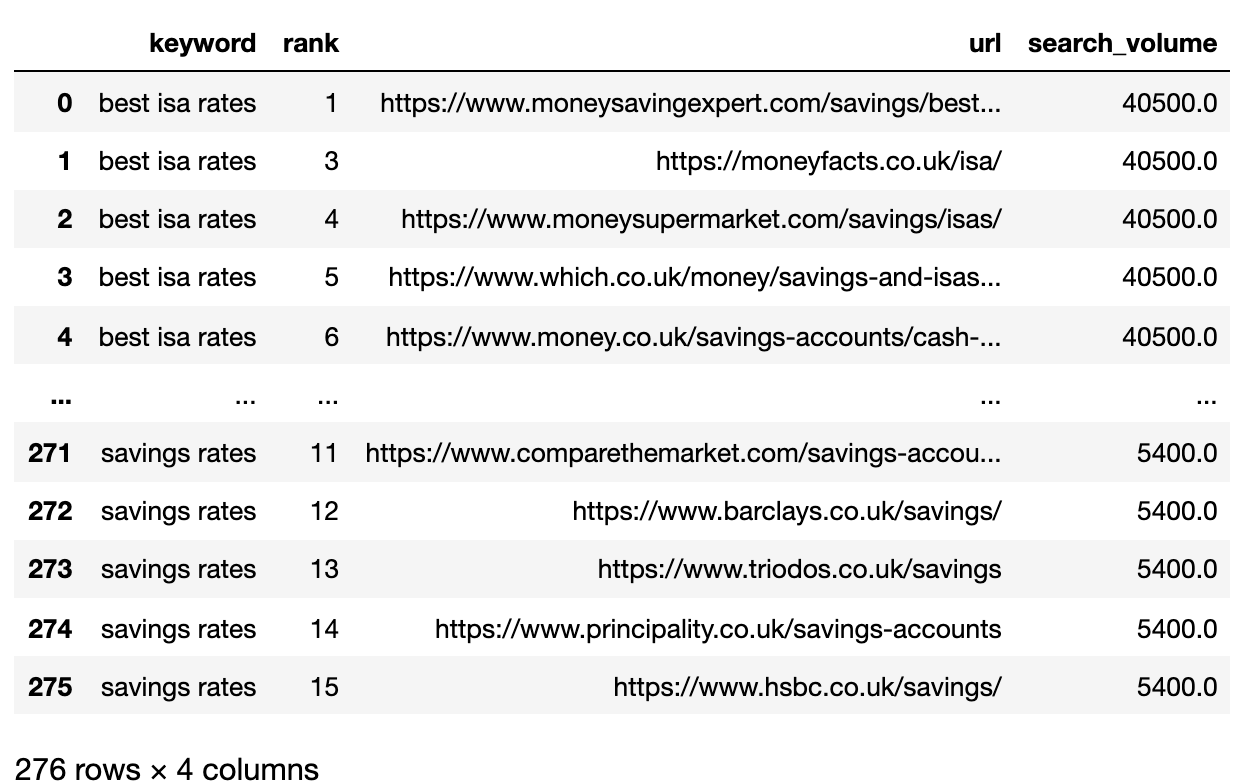 Image de l'auteur, avril 2025
Image de l'auteur, avril 20253. Convert Ranking URLs To A String
Because there are more SERP result URLs than keywords, we need to compress those URLs into a single line to represent the keyword’s SERP.
Here’s how:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Ci-dessous montre le SERP compressé en une seule ligne pour chaque mot-clé.
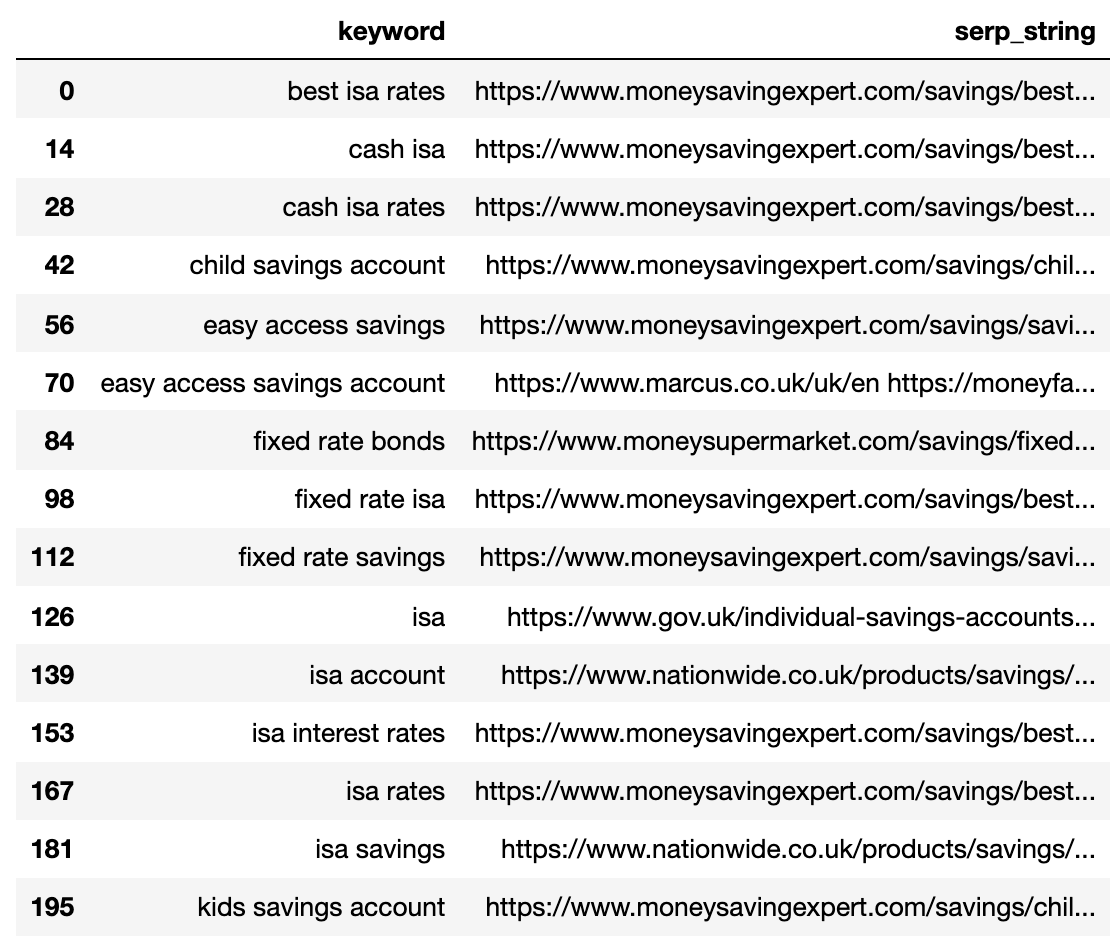 Image de l'auteur, avril 2025
Image de l'auteur, avril 20254. Comparez la distance du serp
Pour effectuer la comparaison, nous avons maintenant besoin de chaque combinaison de mots clés serp associé à d'autres paires:
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

The above shows all of the keyword SERP pair combinations, making it ready for SERP string comparison.
There is no open-source library that compares list objects by order, so the function has been written for you below.
The function “serp_compare” compares the overlap of sites and the order of those sites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]

Now that the comparisons have been executed, we can start clustering keywords.
We will be treating any keywords that have a weighted similarity of 40% or more.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
Nous avons maintenant le nom de sujet potentiel, la similitude des mots clés Serp et les volumes de recherche de chacun.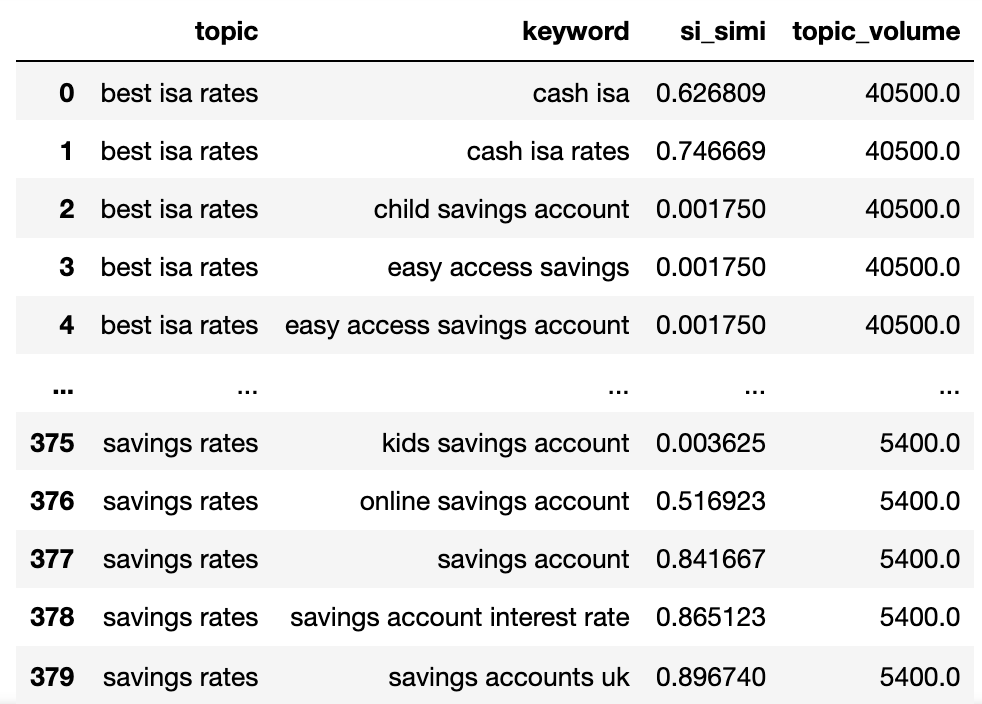
Vous noterez que le mot-clé et le mot clé_b ont été renommés respectivement en thème et en mots clés.
Maintenant, nous allons itérer les colonnes dans le DataFrame en utilisant la technique Lambda.
La technique Lambda est un moyen efficace d'itérer sur les lignes dans un Pandas Dataframe car il convertit les lignes en une liste par opposition à la fonction .Itterrows ().
Voici:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
elif len(sim_topic_groups[keyw]) < len(sim_topic_groups[topc]):
sim_topic_groups[topc].append(keyw)
[sim_topic_groups[topc].append(x) for x in sim_topic_groups.get(keyw)]
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups[keyw]) == len(sim_topic_groups[topc]):
if sim_topic_groups[keyw] == topc and sim_topic_groups[topc] == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups[keyw] = [keyw]
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups[topc] = [topc]
Ci-dessous montre un dictionnaire contenant tous les mots clés regroupés par l'intention de recherche en groupes numérotés:
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}Ressons cela dans un dataframe:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
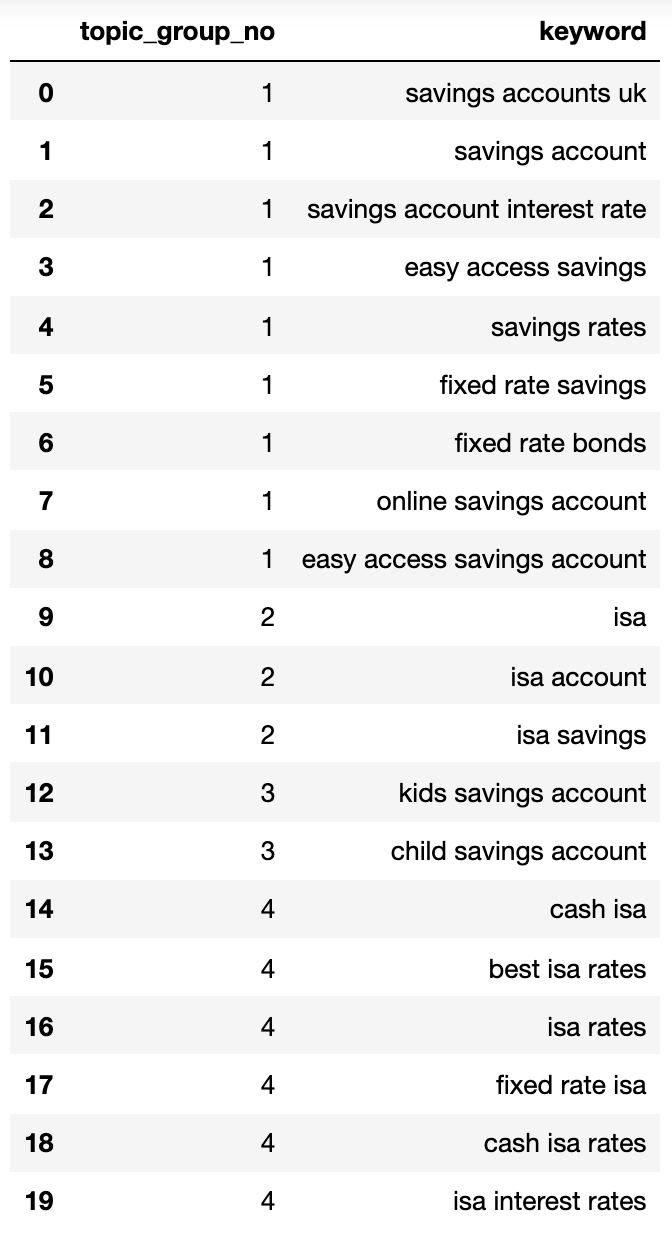 Image de l'auteur, avril 2025
Image de l'auteur, avril 2025Les groupes d'intention de recherche ci-dessus montrent une bonne approximation des mots clés à l'intérieur, ce qu'un expert SEO réaliserait probablement.
Bien que nous n'ayons utilisé qu'un petit ensemble de mots clés, la méthode peut évidemment être mise à l'échelle à des milliers (sinon plus).
Activer les sorties pour améliorer votre recherche
Bien sûr, ce qui précède pourrait être pris davantage à l'aide de réseaux de neurones, en traitant le contenu de classement pour des grappes plus précises et des noms de groupe de grappes, comme certains produits commerciaux le font déjà.
Pour l'instant, avec cette sortie, vous pouvez:
- Incorporez cela dans vos propres systèmes de tableau de bord de référencement pour rendre vos tendances et vos rapports SEO plus significatifs.
- Créez des campagnes de recherche mieux payées en structurant vos comptes Google Ads par recherche de recherche pour un score de qualité supérieure.
- Fusionner les URL de recherche de commerce électronique des facettes redondantes.
- Structure la taxonomie d'un site d'achat en fonction de l'intention de recherche au lieu d'un catalogue de produits typique.
Je suis sûr qu'il y a plus d'applications que je n'ai pas mentionnées – n'hésitez pas à commenter les importantes que je n'ai pas déjà mentionnées.
Dans tous les cas, votre recherche de mots clés de référencement est devenu un peu plus évolutif, précis et plus rapide!
Télécharger le Code complet ici pour votre propre usage.
Plus de ressources:
Image en vedette: Buch et Bee / Shutterstock