
Vous vous demandez pourquoi certaines de vos pages n’apparaissent pas dans Google ?
Les problèmes de crawlabilité pourraient être le coupable.
Dans ce guide, nous expliquerons quels sont les problèmes d’exploration, comment ils affectent le référencement et comment les résoudre.
Commençons.
Quels sont les problèmes de crawlabilité ?
Les problèmes d’exploration sont des problèmes qui empêchent les moteurs de recherche d’accéder aux pages de votre site Web.
Lorsque les moteurs de recherche tels que Google explorent votre site, ils utilisent des robots automatisés pour lire et analyser vos pages.

S’il y a des problèmes de crawlabilité, ces robots peuvent rencontrer des obstacles qui entravent leur capacité à accéder correctement à vos pages.
Les problèmes d’exploration courants incluent :
- Liens sans suivi
- Boucles de redirection
- Mauvaise structure du site
- Vitesse lente du site
Comment les problèmes de crawlabilité affectent-ils le référencement ?
Les problèmes de crawlabilité peuvent affecter considérablement votre jeu SEO.
Les moteurs de recherche agissent comme des explorateurs lorsqu’ils parcourent votre site Web, essayant de trouver autant de contenu que possible.
Mais si votre site a des problèmes de crawlabilité, certaines (ou toutes) pages sont pratiquement invisibles pour les moteurs de recherche.
Ils ne peuvent pas les trouver. Ce qui signifie qu’ils ne peuvent pas les indexer, c’est-à-dire les enregistrer pour les afficher dans les résultats de recherche.

Cela signifie une perte de trafic et de conversions potentiels des moteurs de recherche (organiques).
Vos pages doivent être à la fois explorables et indexables afin de se classer dans les moteurs de recherche.
11 problèmes de crawlabilité et comment les résoudre
1. Pages bloquées dans Robots.txt
Les moteurs de recherche examinent d’abord votre fichier robots.txt. Cela leur indique quelles pages ils peuvent et ne peuvent pas explorer.
Si votre fichier robots.txt ressemble à ceci, cela signifie que l’exploration de tout votre site Web est bloquée :
User-agent: *
Disallow: /
Résoudre ce problème est simple. Remplacez la directive « disallow » par « allow ». Ce qui devrait permettre aux moteurs de recherche d’accéder à l’intégralité de votre site Web.
User-agent: *
Allow: /
Dans d’autres cas, seules certaines pages ou sections sont bloquées. Par exemple:
User-agent: *
Disallow: /products/
Ici, toutes les pages du sous-dossier « produits » sont bloquées.
Résolvez ce problème en supprimant le sous-dossier ou la page spécifié. Les moteurs de recherche ignorent la directive vide « disallow ».
User-agent: *
Disallow:
Alternativement, vous pouvez utiliser la directive « autoriser » au lieu de « interdire » pour demander aux moteurs de recherche d’explorer l’intégralité de votre site. Comme ça:
User-agent: *
Allow: /
Note: Il est courant de bloquer certaines pages de votre fichier robots.txt que vous ne souhaitez pas classer dans les moteurs de recherche, telles que les pages d’administration et de remerciement. C’est un problème d’exploration uniquement lorsque vous bloquez des pages censées être visibles dans les résultats de recherche.
2. Liens sans suivi
La balise nofollow indique aux moteurs de recherche de ne pas explorer les liens d’une page Web.
La balise ressemble à ceci :
<meta name="robots" content="nofollow">
Si cette balise est présente sur vos pages, les liens qu’elle contient peuvent généralement ne pas être explorés.
Cela crée des problèmes d’exploration sur votre site.
Analysez votre site Web avec l’outil d’audit de site de Semrush pour vérifier les liens nofollow.
Ouvrez l’outil, entrez votre site Web et cliquez sur « Commencer Audit.”

La fenêtre « Paramètres d’audit du site » apparaîtra.

De là, configurez les paramètres de base et cliquez sur « Commencer Placer Audit.”
Une fois l’audit terminé, accédez au « Questions» et recherchez « nofollow ».
Pour voir s’il y a des liens nofollow détectés sur votre site.

Si des liens nofollow sont détectés, cliquez sur « XXX liens internes sortants contiennent l’attribut nofollow” pour afficher une liste des pages qui ont une balise nofollow.

Passez en revue les pages et supprimez les balises nofollow si elles ne devraient pas être là.
3. Mauvaise architecture du site
L’architecture du site est la façon dont vos pages sont organisées.
Une architecture de site robuste garantit que chaque page est à quelques clics de la page d’accueil et qu’il n’y a pas de pages orphelines (c’est-à-dire des pages sans liens internes pointant vers elles). Les sites avec une architecture de site solide garantissent que les moteurs de recherche peuvent facilement accéder à toutes les pages.

Une mauvaise architecture de site peut créer des problèmes d’exploration. Notez l’exemple de structure de site illustré ci-dessous. Il a des pages orphelines.

Il n’y a pas de chemin lié permettant aux moteurs de recherche d’accéder à ces pages à partir de la page d’accueil. Ils peuvent donc passer inaperçus lorsque les moteurs de recherche parcourent le site.
La solution est simple : Créez une structure de site qui organise logiquement vos pages dans une hiérarchie avec des liens internes.
Comme ça:

Dans l’exemple ci-dessus, la page d’accueil renvoie à des catégories, qui renvoient ensuite à des pages individuelles de votre site.
Et fournissez un chemin clair aux crawlers pour trouver toutes vos pages.
4. Manque de liens internes
Les pages sans liens internes peuvent créer des problèmes d’exploration.
Les moteurs de recherche auront du mal à découvrir ces pages.
Identifiez vos pages orphelines. Et ajoutez-leur des liens internes pour éviter les problèmes de crawlabilité.
Trouvez des pages orphelines à l’aide de l’outil d’audit de site de Semrush.
Configurez l’outil pour exécuter votre premier audit.
Une fois l’audit terminé, rendez-vous dans la section « Questions» et recherchez « orphelin ».
Vous verrez s’il y a des pages orphelines présentes sur votre site.

Pour résoudre ce problème potentiel, ajoutez des liens internes vers des pages orphelines à partir des pages pertinentes de votre site.
5. Mauvaise gestion du sitemap
Un sitemap fournit une liste des pages de votre site que vous souhaitez que les moteurs de recherche crawlindex et rang.
Si votre sitemap exclut des pages destinées à être explorées, elles peuvent passer inaperçues. Et créer des problèmes de crawlabilité.
Résolvez en recréant un sitemap qui inclut toutes les pages destinées à être explorées.
Un outil tel que Plans de site XML peut aider.
Entrez l’URL de votre site Web et l’outil générera automatiquement un plan du site pour vous.

Ensuite, enregistrez le fichier sous « sitemap.xml » et téléchargez-le dans le répertoire racine de votre site Web.
Par exemple, si votre site Web est www.example.com, l’URL de votre sitemap doit être accessible à l’adresse www.example.com/sitemap.xml.
Enfin, soumettez votre sitemap à Google dans votre compte Google Search Console.
Cliquez sur « Plans de site” dans le menu de gauche. Entrez l’URL de votre sitemap et cliquez sur « Soumettre.”

6. Balises « sans index »
Une balise meta robots « noindex » indique aux moteurs de recherche de ne pas indexer la page.
La balise ressemble à ceci :
<meta name="robots" content="noindex">
Bien que la balise « noindex » soit destinée à contrôler l’indexation, elle peut créer des problèmes d’exploration si vous la laissez sur vos pages pendant une longue période.
Google traite balises « noindex » à long terme comme « nofollow », comme l’a confirmé John Muller de Google.
Au fil du temps, Google cessera complètement d’explorer les liens de ces pages.
Ainsi, si vos pages ne sont pas explorées, les balises « noindex » à long terme pourraient en être la cause.
Identifiez les pages avec une balise « noindex » à l’aide de l’outil d’audit de site de Semrush.
Configurez un projet dans l’outil et exécutez votre premier crawl.
Une fois le crawl terminé, rendez-vous sur le «Questions» et recherchez « noindex ».
L’outil listera les pages de votre site avec une balise « noindex ».

Passez en revue les pages et supprimez la balise « noindex » le cas échéant.
Note: Avoir une balise « noindex » sur certaines pages – les pages de destination au paiement par clic (PPC) et les pages de remerciement, par exemple – est une pratique courante pour les garder hors de l’index de Google. C’est un problème uniquement lorsque vous n’indexez pas les pages destinées à être classées dans les moteurs de recherche. Supprimez la balise « noindex » sur ces pages pour éviter les problèmes d’indexation et d’exploration.
7. Vitesse lente du site
La vitesse du site est la vitesse à laquelle votre site se charge. La lenteur de la vitesse du site peut avoir un impact négatif sur l’exploration.
Lorsque les robots des moteurs de recherche visitent votre site, ils disposent d’un temps limité pour explorer, ce que l’on appelle communément un budget d’exploration.
La vitesse lente du site signifie que le chargement des pages prend plus de temps. Et réduit le nombre de pages que les robots peuvent explorer au cours de cette session d’exploration.
Ce qui signifie que des pages importantes pourraient être exclues de l’exploration.
Essayez de résoudre ce problème en améliorant les performances et la vitesse globales de votre site Web.
Commencez par notre guide d’optimisation de la vitesse des pages.
8. Liens rompus internes
Les liens brisés sont des hyperliens qui pointent vers des pages mortes de votre site.
Ils renvoient une « erreur 404 » comme ceci :

Les liens brisés peuvent avoir un impact significatif sur la capacité d’exploration du site Web.
Les robots des moteurs de recherche suivent les liens pour découvrir et parcourir plus de pages sur votre site Web.
Un lien brisé agit comme une impasse et empêche les robots des moteurs de recherche d’accéder à la page liée.
Cette interruption peut entraver l’exploration approfondie de votre site Web.
Pour trouver des liens brisés sur votre site, utilisez l’outil d’audit de site.
Naviguez jusqu’au « Questions » et recherchez « cassé ».
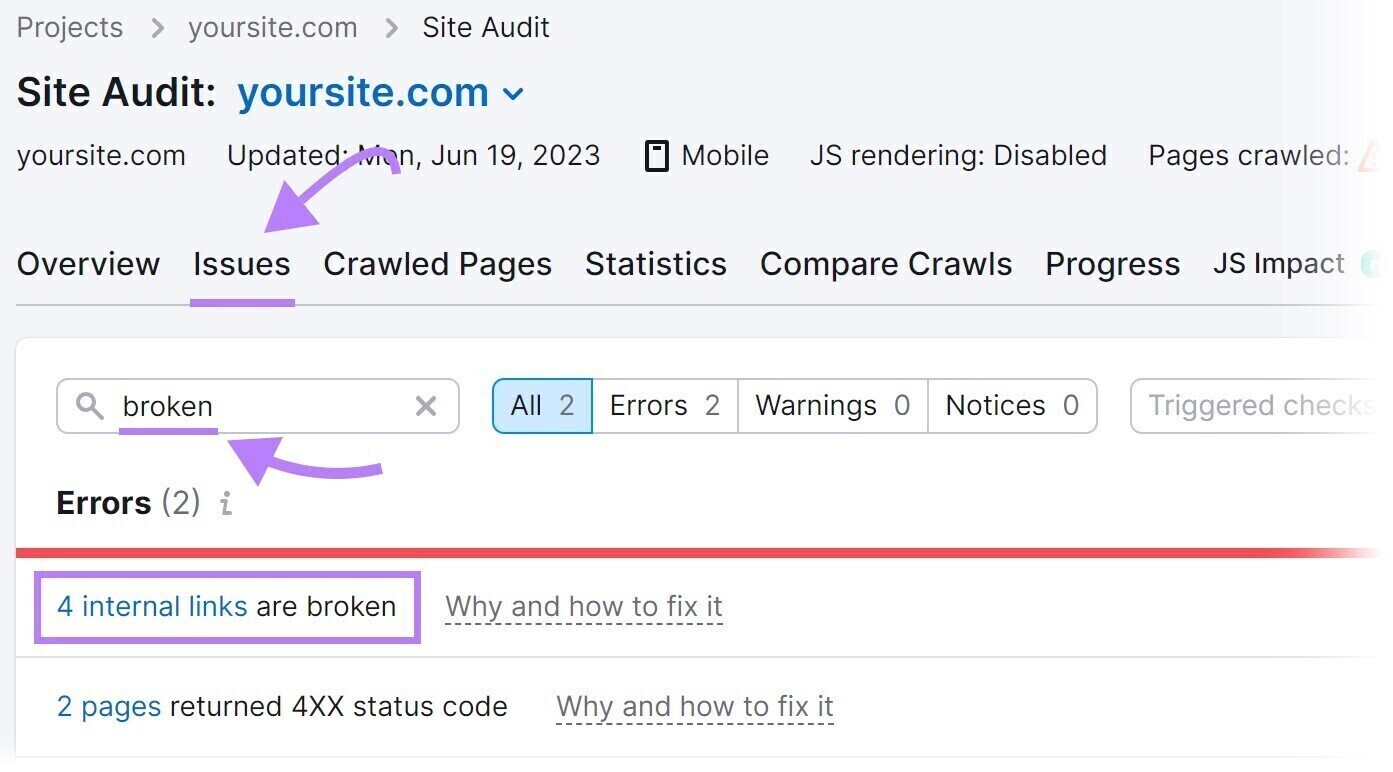
Ensuite, cliquez sur « # liens internes sont rompus.” Vous verrez un rapport répertoriant tous vos liens brisés.

Pour réparer les liens brisés, modifiez le lien, restaurez la page manquante ou ajoutez une redirection 301 vers une autre page pertinente de votre site.
9. Erreurs côté serveur
Les erreurs côté serveur, telles qu’un code d’état HTTP 500, perturbent le processus d’exploration.
Les erreurs côté serveur indiquent que le serveur n’a pas pu répondre à la demande, ce qui rend difficile l’accès et l’exploration du contenu de votre site Web par les bots.
Surveillez régulièrement la santé du serveur de votre site Web pour identifier et résoudre les erreurs côté serveur.
L’outil d’audit de site de Semrush peut vous aider.
Recherchez « 5xx » dans le « Questions” pour vérifier les erreurs côté serveur.

Si des erreurs sont présentes, cliquez sur « # pages ont renvoyé un code d’état 5XX” pour afficher une liste complète des pages concernées.
Ensuite, envoyez cette liste à votre développeur pour configurer correctement le serveur.
10. Boucles de redirection
Une boucle de redirection se produit lorsqu’une page redirige vers une autre, qui à son tour redirige vers la page d’origine, formant une boucle continue.

Les boucles de redirection piègent les robots des moteurs de recherche dans un cycle sans fin de redirections entre deux (ou plusieurs) pages.
Les robots continuent de suivre les redirections sans atteindre la destination finale, ce qui fait perdre un temps crucial au budget d’exploration qui pourrait être consacré à des pages importantes.
Résolvez en identifiant et en corrigeant les boucles de redirection sur votre site.
L’outil d’audit de site peut vous aider.
Recherchez « redirect » dans le « Questionsonglet « .

L’outil affichera les boucles de redirection et offrira des conseils sur la façon de les corriger.

11. Restrictions d’accès
Les pages avec des restrictions d’accès, telles que celles derrière les formulaires de connexion ou les paywalls, peuvent empêcher les robots des moteurs de recherche d’explorer et d’indexer ces pages.
Par conséquent, ces pages peuvent ne pas apparaître dans les résultats de recherche, ce qui limite leur visibilité pour les utilisateurs.
Il est logique d’avoir certaines pages restreintes. Par exemple, les sites Web basés sur l’adhésion ou les plateformes d’abonnement ont souvent des pages restreintes qui ne sont accessibles qu’aux membres payants ou aux utilisateurs enregistrés.
Cela permet au site de fournir du contenu exclusif, des offres spéciales ou des expériences personnalisées. Pour créer un sentiment de valeur et inciter les utilisateurs à s’abonner ou à devenir membres.
Mais si des parties importantes de votre site Web sont restreintes, il s’agit d’une erreur d’exploration.
Évaluer la nécessité d’un accès restreint pour chaque page. Gardez les restrictions sur les pages qui en ont vraiment besoin. Supprimer les restrictions sur les autres.
Débarrassez votre site Web des problèmes de crawlabilité
Les problèmes de crawlabilité affectent vos performances SEO.
L’outil d’audit de site de Semrush est une solution unique pour détecter et résoudre les problèmes qui affectent l’exploration.
Inscrivez-vous gratuitement pour commencer.