
L'un des principaux avantages de la combinaison des compétences en programmation et en référencement réside dans le fait que vous pouvez trouver des solutions intelligentes qu'il serait difficile de voir si vous ne connaissez que le référencement ou la programmation séparément.
Par exemple, le suivi de l'indexation de vos pages les plus importantes est une tâche cruciale de référencement.
S'ils ne sont pas indexés, vous devez connaître la raison et prendre des mesures. La meilleure partie est que nous pouvons apprendre tout cela gratuitement directement depuis la console de recherche Google.
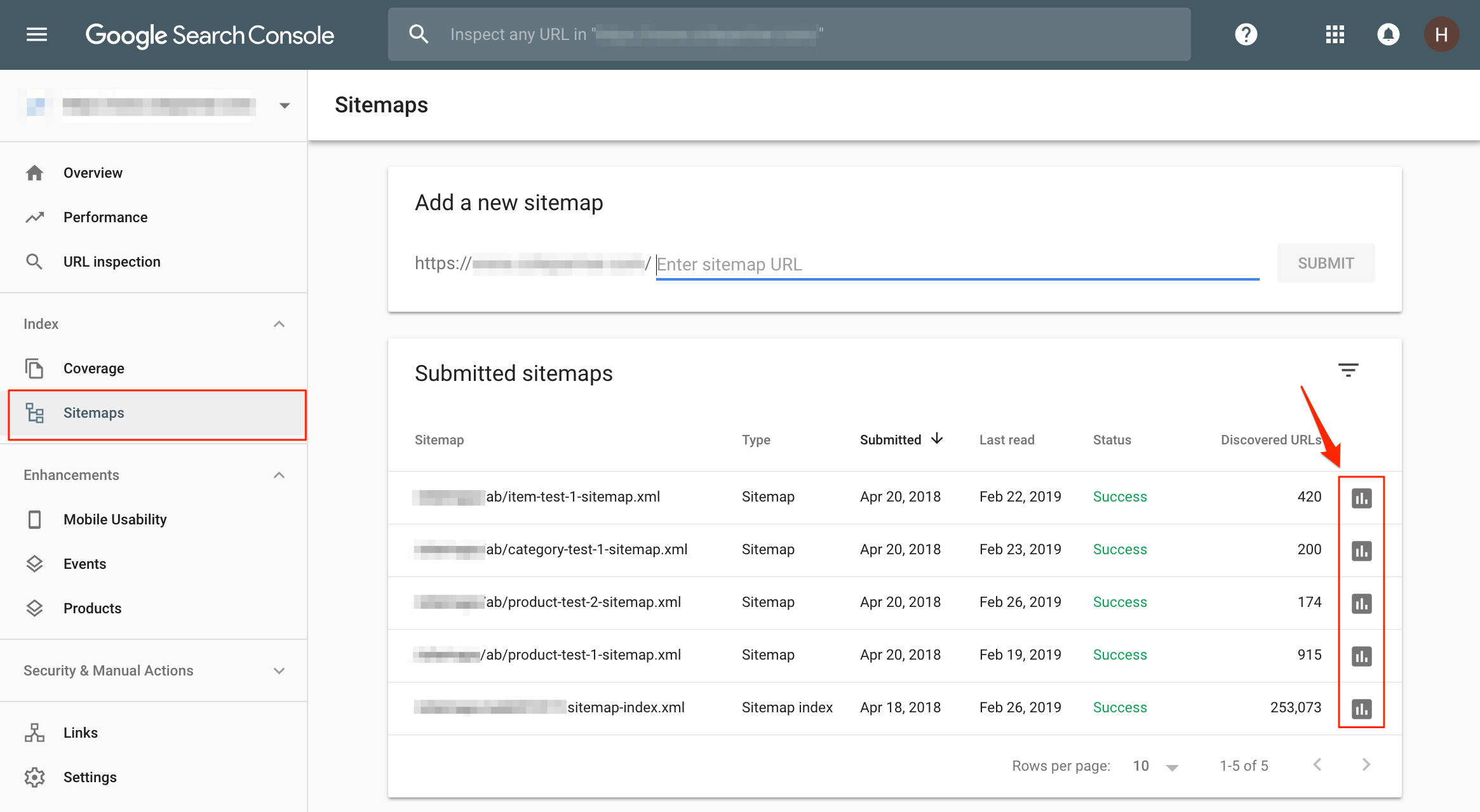

Dans la capture d'écran ci-dessus, les sitemaps XML sont regroupés par type de page, mais les quatre sitemaps répertoriés ici sont spécifiquement utilisés pour suivre la progression de certains tests de référencement A / B que nous avons exécutés pour ce client.
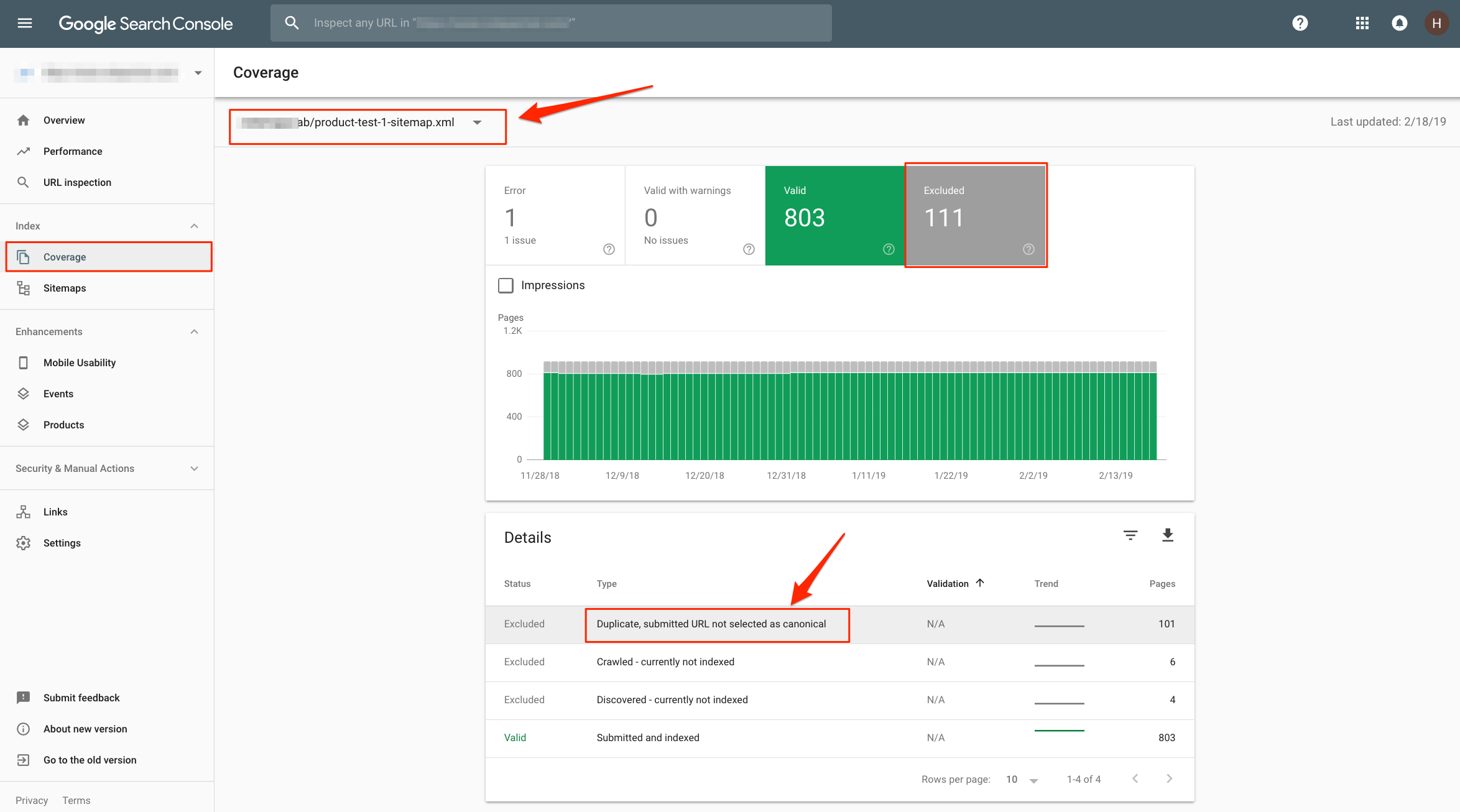

Dans les rapports de couverture d'index, nous pouvons vérifier chaque sitemap, savoir quelles pages spécifiques ne sont pas indexées, pourquoi elles ne sont pas indexées et avoir une idée de la façon de les réparer (si elles peuvent être corrigées).
Le reste de cet article explique comment réorganiser vos sitemaps XML à l'aide de tout critère permettant d'identifier les problèmes d'indexation sur les pages qui vous tiennent à cœur.
Table des matières
Bibliothèques requises
Dans cet article, nous allons utiliser Python 3 et les bibliothèques tierces suivantes:
Si vous avez utilisé Google Colab, vous devez mettre à niveau vos pandas. Type:
! pip install –grade pandas == 0.23
Processus général
Nous allons lire les URL des sitemaps XML existants, les charger dans les cadres de données pandas, créer ou utiliser des colonnes supplémentaires, regrouper les URL par les colonnes que nous utiliserons comme critères et écrire les groupes d’URL dans des sitemaps XML.
Lire les URL de sitemap à partir d'index XML de sitemap
Commençons par lire une liste d’URL de sitemap dans le journal du moteur de recherche. sitemap index.
La sortie partielle est:
Le nombre de sitemaps sont 30
{'Https://www.searchenginejournal.com/post-sitemap1.xml': '2005-08-15T10: 52: 01-04: 00',…
Ensuite, nous les chargeons dans un bloc de données de pandas.
La sortie affiche les 10 premières URL avec leur horodatage de dernière modification.
Lire des URL à partir de sitemaps XML
Maintenant que nous avons des URL de plan de site, nous pouvons extraire les URL de site Web réelles. Par exemple, nous extrairons uniquement les URL des post-sitemaps.
La sortie partielle est
https://www.searchenginejournal.com/post-sitemap1.xml
Le nombre d'URL sont 969
https://www.searchenginejournal.com/post-sitemap2.xml
Le nombre d'URL sont 958
https://www.searchenginejournal.com/post-sitemap3.xml
Le nombre d'URL sont 943
Réorganisation des sitemaps par mots populaires
Les sitemaps XML de Search Engine Journal utilisent le plug-in Yoast SEO, qui sépare les catégories et les blogs, mais tous les articles sont regroupés dans des fichiers de sitemap post-sitemapX.xml.
Nous voulons réorganiser les post-sitemaps en fonction des mots les plus populaires qui apparaissent dans les slugs. Nous avons créé le nuage de mots que vous voyez ci-dessus avec les mots les plus populaires que nous avons trouvés. Mettons cela ensemble!
Créer un nuage de mots


Afin d'organiser les sitemaps en fonction de leurs URL les plus populaires, nous allons créer un nuage de mots. Un nuage de mots n'est que les mots les plus populaires classés par leur fréquence. Nous éliminons les mots courants tels que «le», «a», etc. pour avoir un groupe propre.
Nous créons d’abord une nouvelle colonne avec uniquement les chemins des URL, puis nous téléchargeons les mots vides anglais à partir du paquet Nltk.
Le processus consiste d'abord à ne prendre que la partie chemin des URL, à séparer les mots en utilisant – ou / comme séparateurs et à compter la fréquence des mots. Lors du comptage, nous excluons les mots vides et les mots qui ne sont que des chiffres. Pensez aux 5 de «5 façons de faire X».
La sortie partielle est:
[([([([('Google«4430), (« recherche », 2961), («seo«1482), (« yahoo », 1049) (« marketing », 989), (« nouveau », 919), (« contenu », 919) ((social, 821),…
Juste pour le plaisir (comme promis dans le titre), voici le code qui créera un nuage de mots visuel avec les fréquences de mots ci-dessus.
Maintenant, nous ajoutons le mot nuage colonne en tant que catégorie dans le cadre de données avec les URL de sitemap.
Voici à quoi ressemble la sortie.
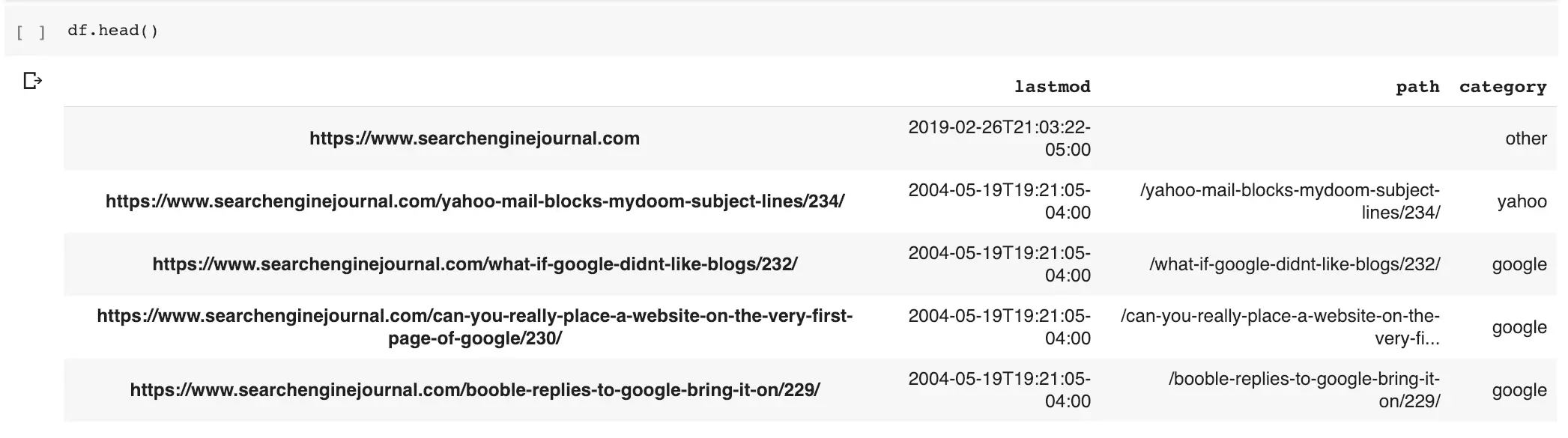

Nous pouvons utiliser cette nouvelle catégorie pour examiner les URL contenant le mot populaire: Google.
df[df[df[df[df[“category”] == “google”]
Cette liste répertorie uniquement les URL contenant ce mot populaire dans le chemin.
Briser la limite de couverture d'index d'URL 1k
Le rapport de couverture d'index de la console de recherche Google est puissant, mais il limite les rapports à un millier d'URL. Nous pouvons fractionner davantage nos URL de sitemaps XML déjà filtrées en groupes d’URL de 1k.
On peut utiliser le puissant pouvoir des pandas indexage capacité pour cela.
Réorganisation des sitemaps par best-sellers
L’une des utilisations les plus puissantes de cette technique consiste à séparer les pages menant à des conversions.
Sur les sites de commerce électronique, nous pourrions identifier les meilleurs vendeurs et savoir lesquels ne sont pas indexés. L'argent facile!
SEJ n'étant pas un site transactionnel, je vais créer de fausses transactions pour illustrer cette tactique. Normalement, vous récupérez ces données à partir de Google Analytics.
Je suppose que les pages contenant les mots « adwords », « facebook », « ads » ou « media » ont des transactions.
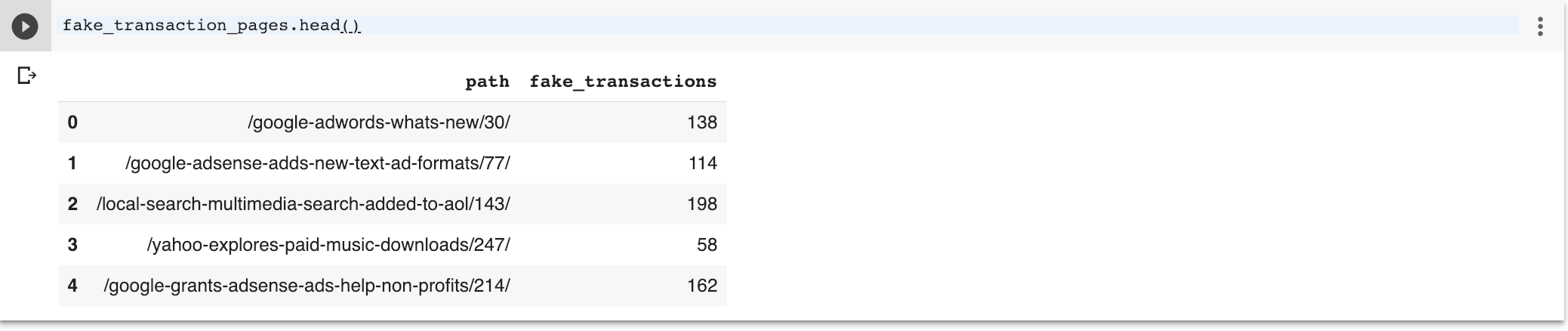

Nous créons une colonne de fausses transactions avec uniquement le chemin relatif que vous trouverez normalement dans Google Analytics.
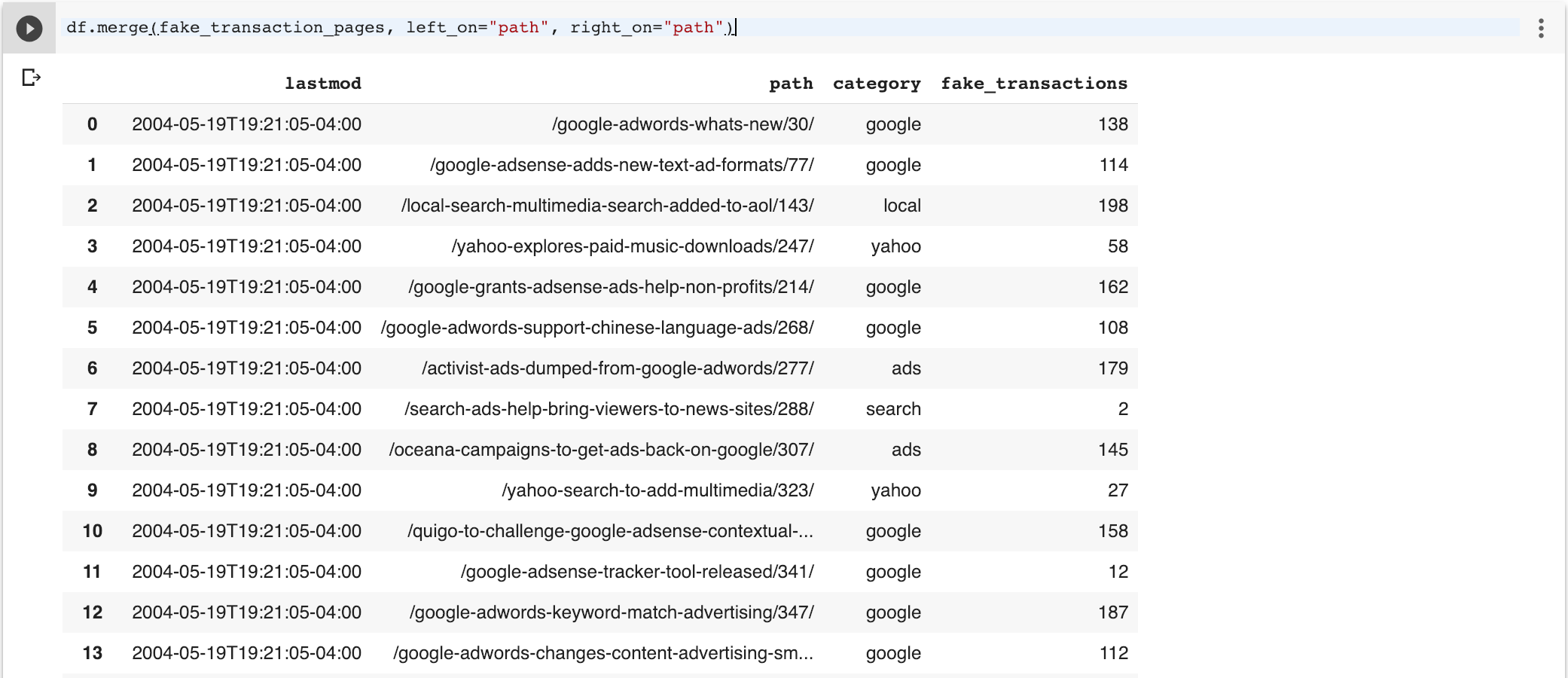
Ensuite, nous allons fusionner les deux trames de données pour ajouter les données de transaction au trame de données du sitemap d'origine. Par défaut, les pandas fusionner function effectuera une jointure interne, de sorte que seules les lignes communes sont disponibles.
df.merge (fake_transaction_pages, left_on = « chemin », right_on = « chemin »)

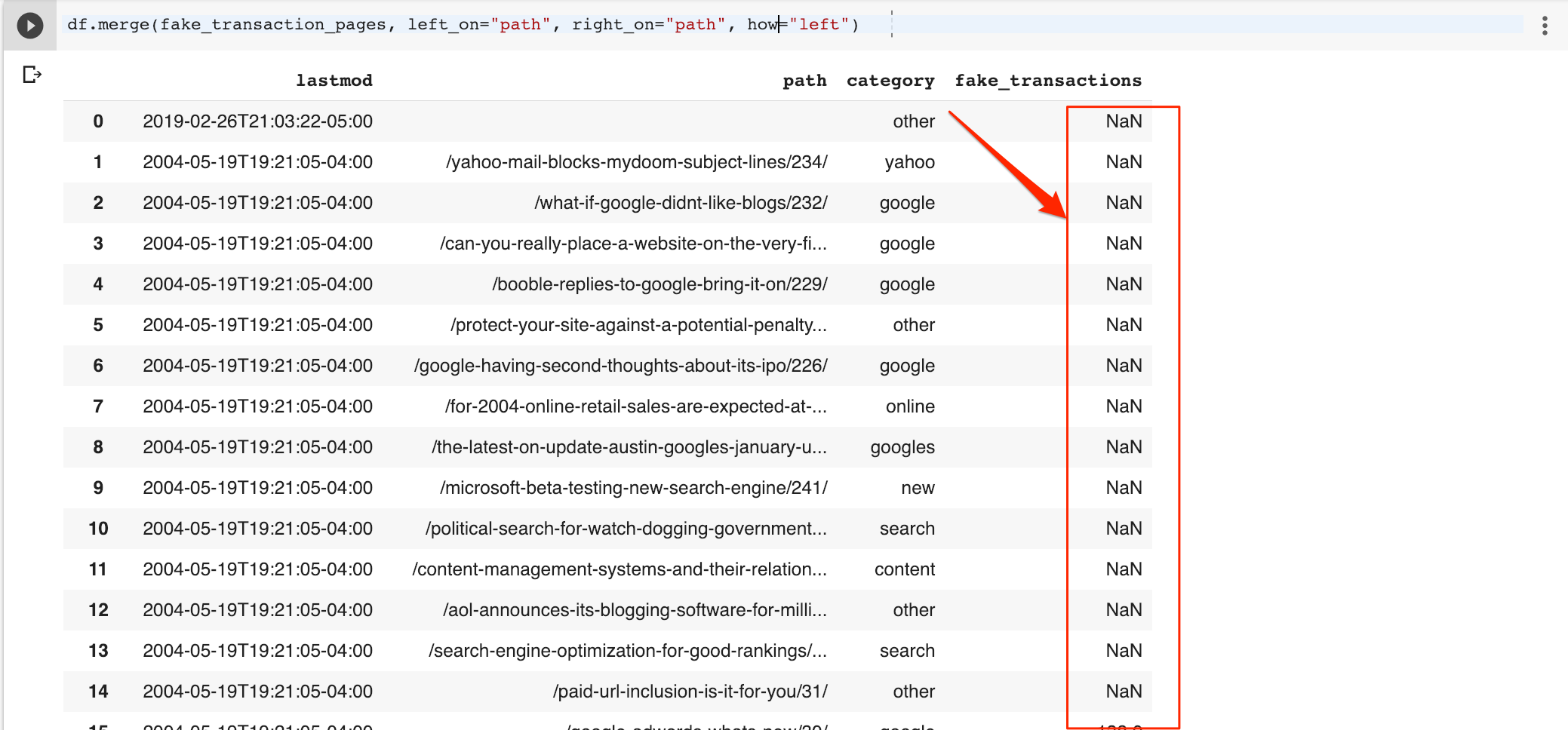
Comme je veux toutes les lignes, je changerai le type de jointure à gauche pour qu'il inclue toutes les lignes du cadre de données d'origine. Notez les lignes manquantes fausses NaN (valeur manquante) dans la colonne de fausses transactions.
df.merge (fake_transaction_pages, left_on = « chemin », right_on = « chemin », comment = « gauche »)

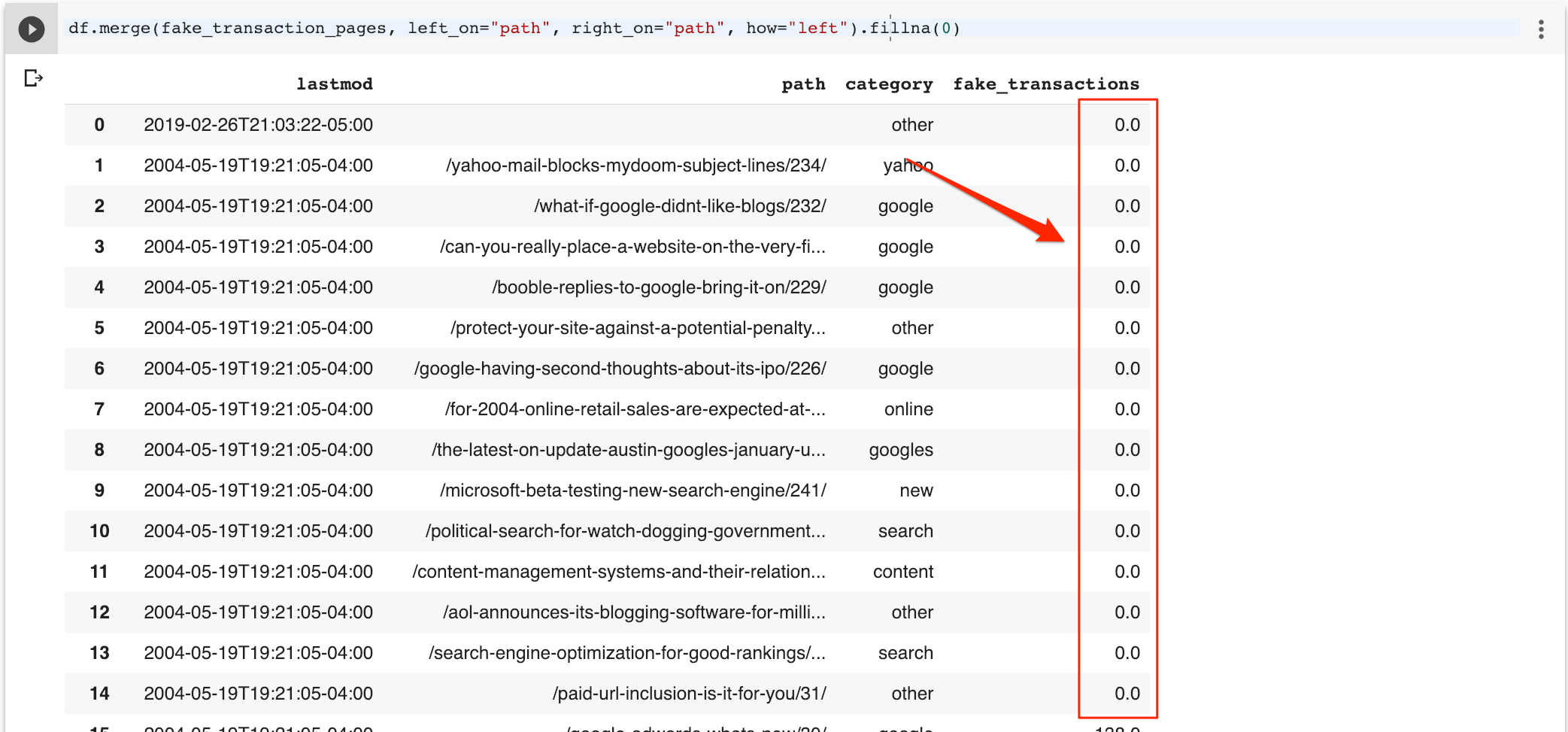
Je peux facilement remplir les valeurs manquantes avec des zéros.
df.merge (fake_transaction_pages, left_on = « chemin », right_on = « chemin », comment = « gauche »).fillna (0)

Je peux maintenant obtenir seulement la liste des meilleurs vendeurs (par transaction) en utilisant ceci.
new_df = df.merge (fake_transaction_pages, left_on = « chemin », right_on = « chemin », comment = « gauche »). fillna (0)
new_df[new_df.fake_transactions > 0]
Écrire des sitemaps XML
Jusqu'à présent, nous avons vu comment grouper des URL à l'aide de blocs de données Pandas utilisant différents critères, mais comment reconvertir ces URL en plans Sitemap XML? Assez facile!
Il y a toujours un moyen difficile de faire les choses et quand il s'agit de créer des sitemaps XML, ce serait d'utiliser BeautifulSoup, lxml ou des bibliothèques similaires pour construire l'arborescence XML à partir de zéro.
Une approche plus simple consiste à utiliser un langage de modélisation semblable à ceux utilisés pour créer des applications Web. Dans notre cas, nous utiliserons un langage de template populaire appelé Jinja2.
Il y a trois composants ici:
- Le modèle avec une boucle for pour itérer un objet de contexte appelé pages. Ce devrait être un tuple Python, où le premier élément est l'URL et le second est le dernier horodatage de modification.
- Notre bloc de données pandas d'origine comporte un index (l'URL) et une colonne (l'horodatage). On peut appeler des pandas itertuples () ce qui créera une séquence qui sera bien rendue sous la forme d’un sitemap XML.
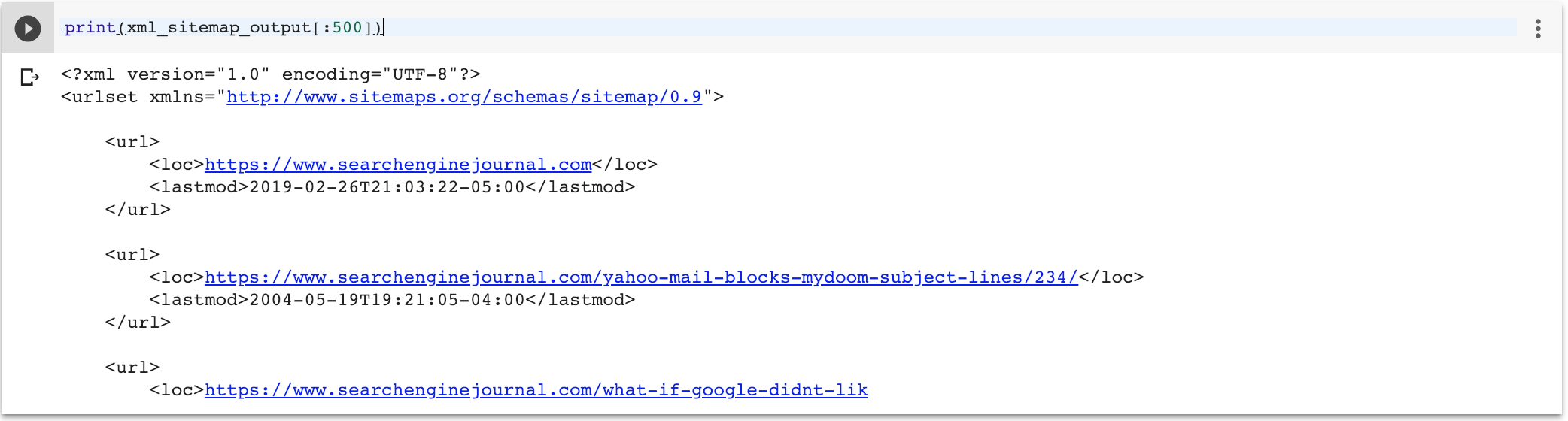

C'est au moins 10 fois plus simple que de créer des sitemaps à partir de rien!
Ressources pour en savoir plus
Comme d’habitude, il ne s’agit que d’un échantillon des éléments intéressants que vous pouvez utiliser lorsque vous ajoutez des scripts Python à votre travail de référencement quotidien. Voici quelques liens à explorer davantage.
Plus de ressources:
Crédits d'image
Captures d'écran prises par l'auteur, février 2019
Nuage de mots généré par l'auteur, février 2019
S'abonner à SEJ
Recevez notre lettre d'information quotidienne de la fondatrice de SEJ, Loren Baker, sur les dernières nouvelles de l'industrie!
