
Dans articles passésJ’ai expliqué comment les compétences en programmation peuvent vous aider à diagnostiquer et à résoudre des problèmes complexes, à mélanger des données provenant de différentes sources et même à automatiser votre travail de référencement.
Dans cet article, nous allons utiliser les compétences en programmation que nous avons développées apprendre en faisant / codant.
Plus précisément, nous allons examiner de près l'un des problèmes techniques de référencement les plus impactants que vous puissiez résoudre: identifier et supprimer les pièges des chenilles.
Nous allons explorer un certain nombre d'exemples – leurs causes, leurs solutions via des extraits de code HTML et Python.
De plus, nous ferons quelque chose d’intéressant: écrire un robot simple qui évite les pièges et ne prend que 10 lignes de code Python!
Mon objectif avec cette rubrique est qu’une fois que vous comprenez en profondeur les causes des pièges sur chenilles, vous ne pouvez plus les résoudre après coup, mais aussi aider les développeurs à les empêcher de se produire.
Guide d'introduction aux pièges sur chenilles
Un piège de robot se produit lorsqu'un robot de moteur de recherche ou une araignée SEO commence à saisir un grand nombre d'URL qui ne génèrent pas de nouveau contenu ou de nouveaux liens.
Le problème avec les pièges à chenilles est qu’ils mangent budget d'analyse les moteurs de recherche allouent par site.
Une fois le budget épuisé, le moteur de recherche n'aura plus le temps d'explorer les pages précieuses du site. Cela peut entraîner une perte importante de trafic.
Il s’agit d’un problème courant sur les sites utilisant des bases de données, car la plupart des développeurs ne savent même pas qu’il s’agit d’un problème grave.
Lorsqu'ils évaluent un site du point de vue de l'utilisateur final, il fonctionne correctement et ils ne voient aucun problème. En effet, les utilisateurs finaux sont sélectifs lorsqu'ils cliquent sur des liens, ils ne suivent pas tous les liens d'une page.
Comment fonctionne un robot
Voyons comment un robot navigue sur un site en recherchant et en suivant des liens dans le code HTML.
Ci-dessous le code pour un exemple simple de Scrapy robot basé sur. Je l'ai adapté du code sur leur page d'accueil. N'hésitez pas à suivre leur tutoriel pour en savoir plus sur la construction de robots d'exploration personnalisés.

La première boucle for saisit tous les blocs d’article de la section Derniers articles et la seconde boucle ne fait que suivre le lien Suivant que je mets en surbrillance avec une flèche.
Lorsque vous écrivez un robot sélectif comme celui-ci, vous pouvez facilement sauter la plupart des pièges de ce dernier!
Vous pouvez enregistrer le code dans un fichier local et exécuter l'araignée à partir de la ligne de commande, comme suit:
$ scrapy runspider sejspider.py
Ou d'un script ou d'un cahier Jupyter.
Voici l'exemple de journal de l'exécution du robot d'exploration:
Les robots traditionnels extraient et suivent tous les liens de la page. Certains liens seront relatifs, d'autres absolus, d'autres mèneront à d'autres sites et la plupart à d'autres pages du site.
Le robot doit rendre les URL relatives absolues avant de les explorer, et marquer celles qui ont été visitées pour éviter de les visiter à nouveau.
Un robot de moteur de recherche est un peu plus compliqué que cela. Il est conçu comme un robot distribué. Cela signifie que les analyses de votre site ne proviennent pas d’une machine / IP, mais de plusieurs.
Ce sujet sort du cadre de cet article, mais vous pouvez lire le Documentation Scrapy pour apprendre à mettre en œuvre un programme et à obtenir une perspective encore plus profonde.
Maintenant que vous avez vu le code des robots d'exploration et que vous comprenez comment il fonctionne, explorons quelques pièges courants des robots d'exploration et voyons pourquoi un robot d'exploration les craquerait.
Comment une chenille tombe aux pièges
J’ai compilé une liste de cas courants (et moins fréquents) à partir de ma propre expérience, de la documentation de Google et de quelques articles de la communauté auxquels je renvoie dans la section des ressources. N'hésitez pas à les consulter pour obtenir une image plus grande.
Une solution courante et incorrecte aux interruptions des robots d'exploration consiste à ajouter des méta-robots noindex ou canoniques aux pages dupliquées. Cela ne fonctionnera pas car cela ne réduit pas l’espace de balayage. Les pages doivent encore être explorées. C'est un exemple de la raison pour laquelle il est important de comprendre comment les choses fonctionnent à un niveau fondamental.
Identifiants de session
De nos jours, la plupart des sites Web utilisent des cookies HTTP pour identifier les utilisateurs et les empêchent d'utiliser le site s'ils les désactivent.
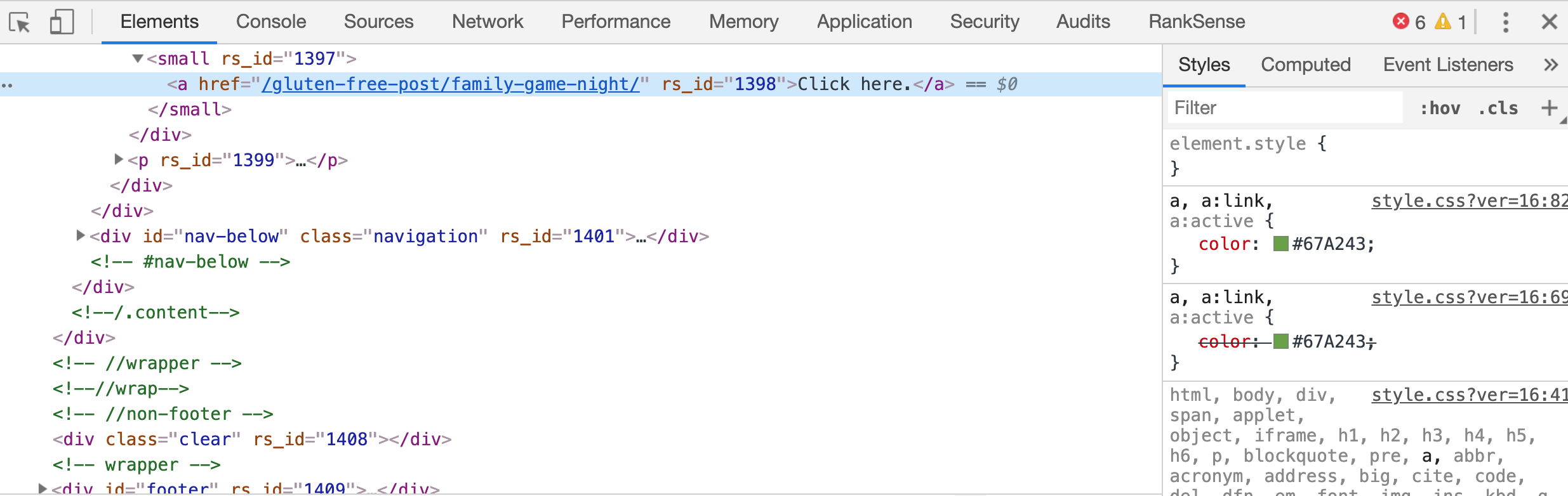
Cependant, de nombreux sites utilisent encore une autre approche pour identifier les utilisateurs: l'ID de session. Cet identifiant est unique par visiteur du site Web et il est automatiquement intégré à toutes les URL de la page.
Lorsqu'un robot de moteur de recherche analyse la page, toutes les URL ont un ID de session, ce qui rend les URL uniques et apparemment dotées d'un nouveau contenu.
Cependant, rappelez-vous que les robots d'exploration des moteurs de recherche sont distribués, les demandes proviennent donc de différentes adresses IP. Cela conduit à des identifiants de session encore plus uniques.
Nous voulons que les robots de recherche explorent:

Mais ils rampent:

Lorsque l'ID de session est un paramètre d'URL, il s'agit d'un problème facile à résoudre car vous pouvez le bloquer dans les paramètres de paramètres d'URL.
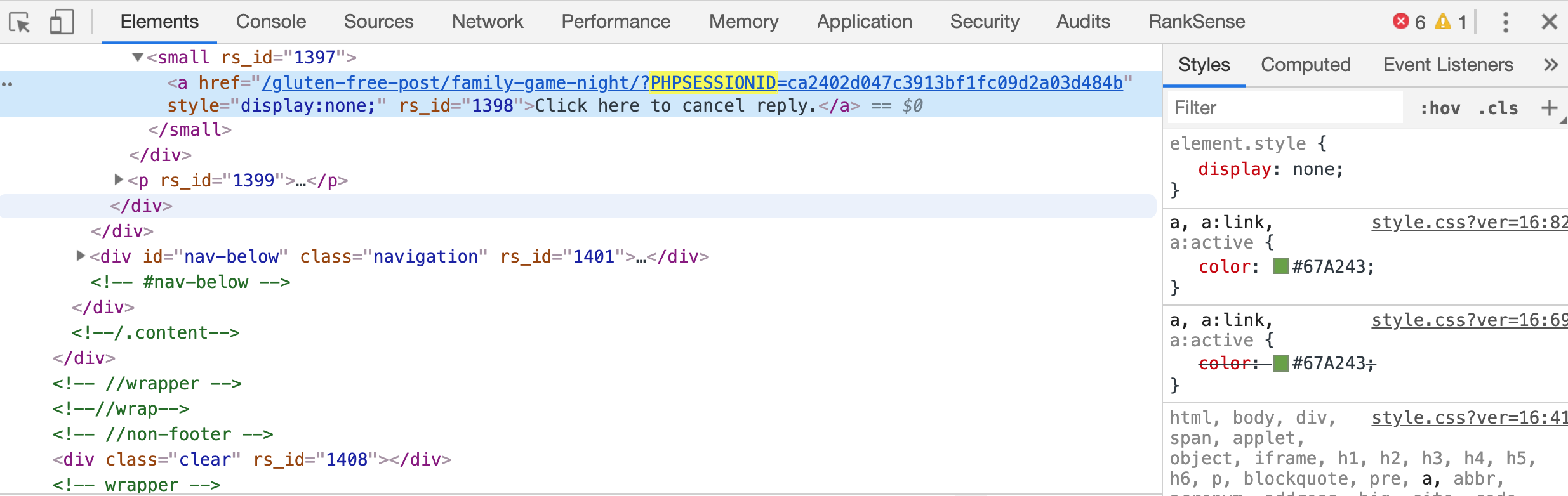
Mais que se passe-t-il si l'ID de session est incorporé dans le chemin d'accès réel des URL? Oui, c'est possible et valide.
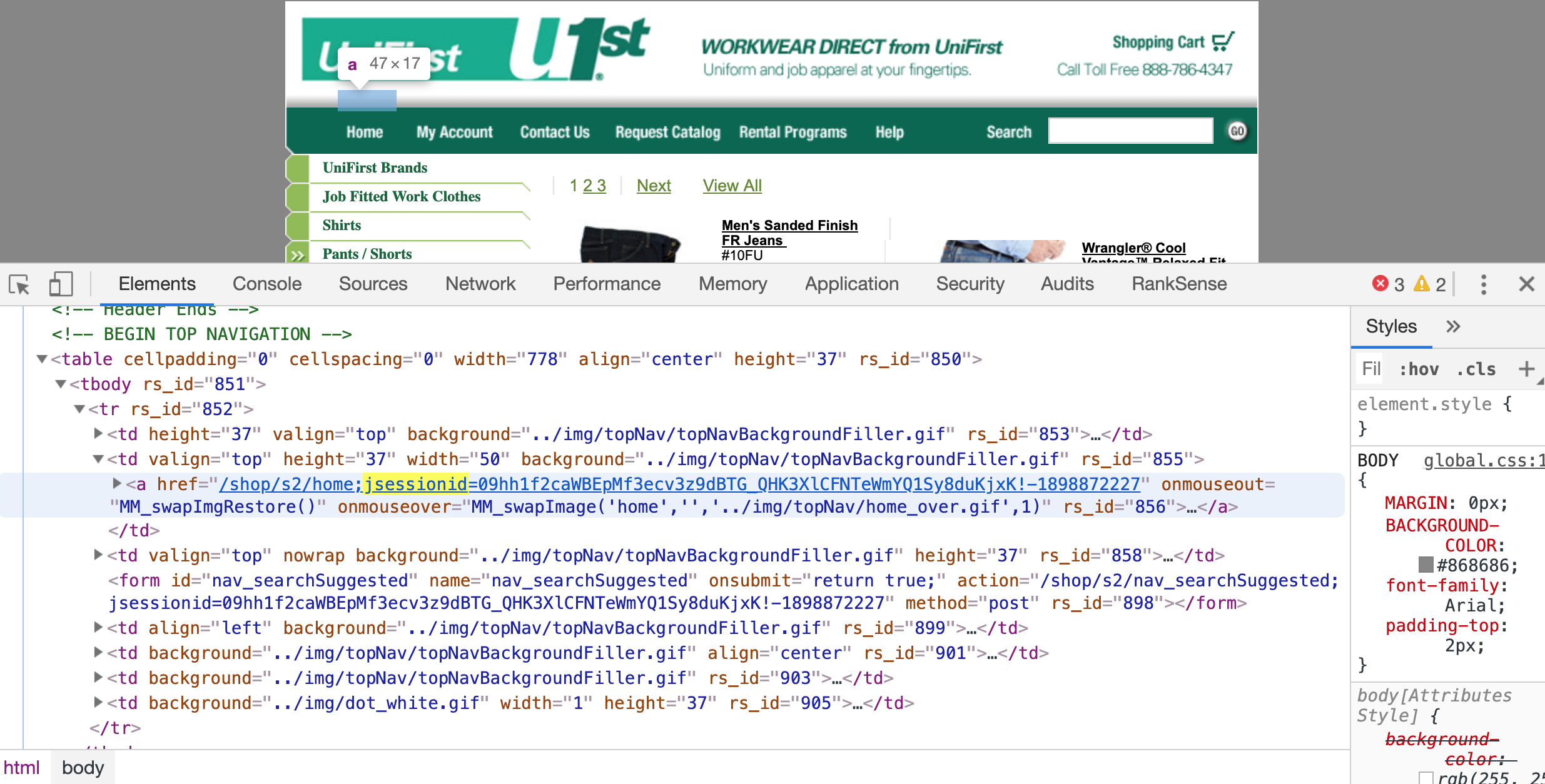

Serveurs Web basés sur la spécification Enterprise Java Beans, utilisés pour ajouter l'ID de session dans le chemin tel que:; jsessionid. Vous pouvez facilement trouver des sites encore indexés avec cela dans leurs URL.

Il n'est pas possible de bloquer ce paramètre lorsqu'il est inclus dans le chemin. Tu dois le réparer à la source.
Maintenant, si vous écrivez votre propre robot d'exploration, vous pouvez facilement l'ignorer avec ce code
Navigation à facettes
Navigation à facettes ou guidée, qui sont très courants sur les sites de commerce électronique, sont probablement la source la plus courante de pièges à chenilles sur les sites modernes.
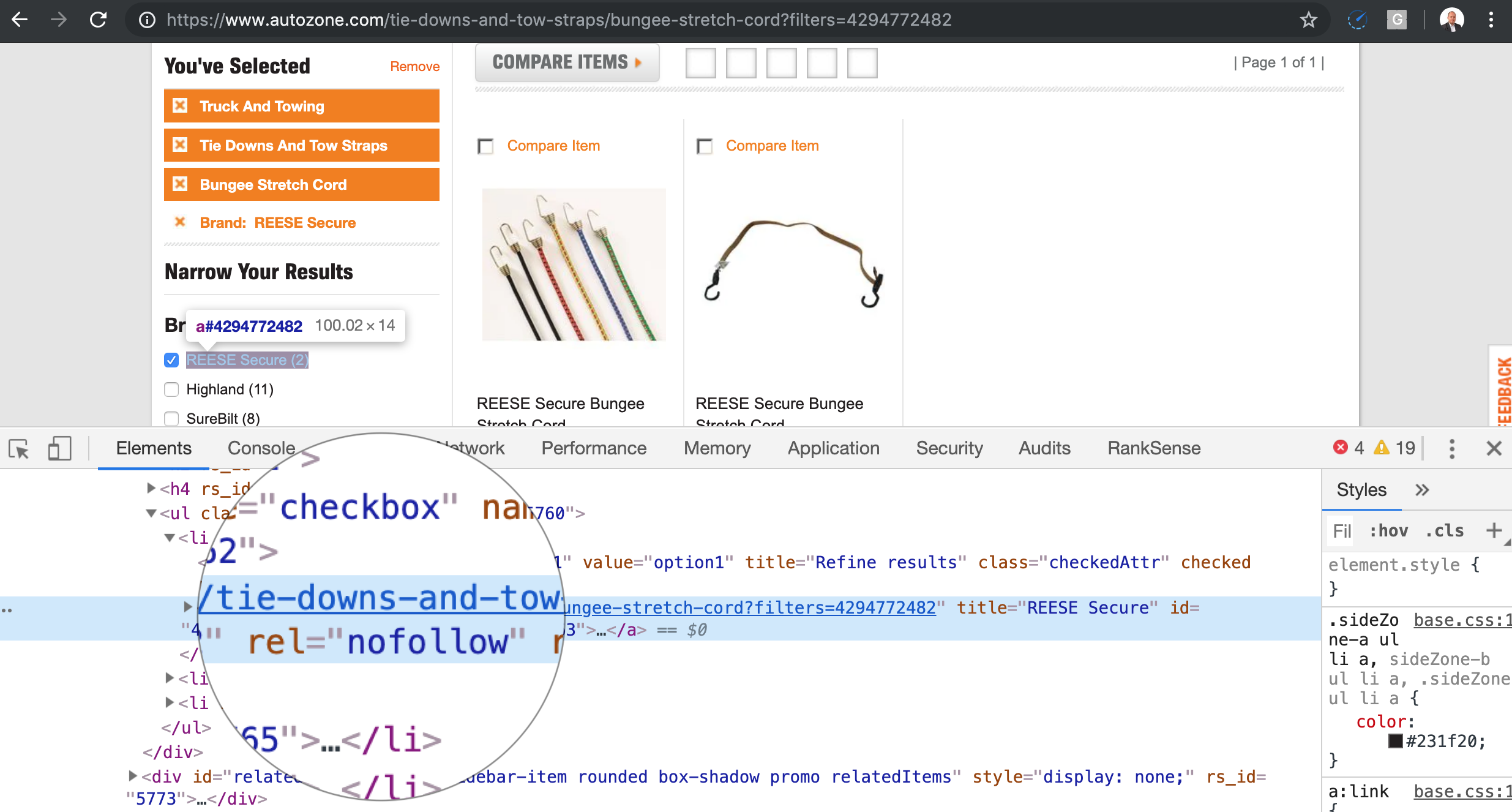

Le problème est qu'un utilisateur régulier ne fait que quelques sélections, mais lorsque nous demandons à notre robot d'exploration de saisir ces liens et de les suivre, il essaie toutes les permutations possibles. Le nombre d'URL à analyser devient un problème combinatoire. Dans l'écran ci-dessus, nous avons X nombre de permutations possibles.
Traditionnellement, vous les générez en utilisant JavaScript, mais comme Google peut les exécuter et les analyser, cela ne suffit pas.
Une meilleure approche consiste à ajouter les paramètres sous forme de fragments d'URL. Les robots d'exploration des moteurs de recherche ignorent les fragments d'URL. Ainsi, l'extrait ci-dessus serait réécrit comme ceci.

Voici le code pour convertir des paramètres spécifiques en fragments.
Nous voyons souvent dans une implémentation de navigation à facettes redoutable la conversion des paramètres d’URL de filtrage en chemins, ce qui rend tout filtrage par chaîne de requête presque impossible.
Par exemple, au lieu de / category? Color = blue, vous obtenez / category / color = blue /.
Liens relatifs défectueux
J'avais l'habitude de voir tellement de problèmes avec les URL relatives, que j'ai recommandé aux clients de toujours rendre toutes les URL absolues. J'ai réalisé par la suite que c'était une mesure extrême, mais laissez-moi montrer avec du code pourquoi les liens relatifs peuvent causer autant de pièges sur les robots d'exploration.
Comme je l'ai mentionné, lorsqu'un robot d'exploration trouve des liens relatifs, il doit les convertir en absolu. Afin de les convertir en absolu, il utilise l'URL source comme référence.
Voici le code pour convertir un lien relatif en absolu.
Maintenant, voyons ce qui se passe lorsque le lien relatif est mal formaté.
Voici le code qui montre le lien absolu qui en résulte.
Maintenant, voici où le piège de chenilles a lieu. Lorsque j'ouvre cette fausse URL dans le navigateur, je ne reçois pas de 404, ce qui indiquerait au robot d'exploration de supprimer la page et de ne suivre aucun lien. Je reçois un soft 404, qui met le piège en mouvement.
Notre lien défectueux dans le pied de page grandira à nouveau lorsque le robot tente de créer une URL absolue.
Le robot continuera à suivre ce processus et la fausse URL continuera de croître jusqu'à atteindre la limite maximale d'URL prise en charge par le logiciel de serveur Web ou le CDN. Cela change selon le système.
Par exemple, IIS et Internet Explorer ne prend pas en charge les URL de plus de 2 048 à 2 083 caractères en longueur.
Il existe un moyen rapide et facile ou long et douloureux d'attraper ce type de piège à chenilles.
Vous connaissez probablement déjà cette approche longue et pénible: lancez une araignée SEO pendant des heures jusqu'à ce qu'elle tombe dans le piège.
Vous savez généralement qu'il en a trouvé une, car il manque de mémoire si vous l'avez exécutée sur votre ordinateur de bureau, ou des millions d'URL ont été trouvées sur un petit site si vous utilisez une base de données en nuage.
Le moyen le plus simple est de rechercher la présence de 414 erreur de code d'état dans les journaux du serveur. La plupart des serveurs Web conformes au W3C renverront un 414 lorsque l'URL demandée est plus longue que nécessaire.
Si le serveur Web ne signale pas 414, vous pouvez également mesurer la longueur des URL demandées dans le journal et filtrer celles qui dépassent 2 000 caractères.
Voici le code pour faire l'un ou l'autre.
Voici une variante de la barre oblique manquante particulièrement difficile à détecter. Cela se produit lorsque vous copiez et collez un code dans un traitement de texte et qu'il remplace le caractère de citation.

Pour l'œil humain, les citations se ressemblent, à moins que vous ne prêtiez une attention particulière. Voyons ce qui se passe lorsque le robot analyse cela, apparemment, corrige l'URL relative en absolu.
Mise en cache
Cache de cache est une technique utilisée par les développeurs pour forcer les CDN (Content Delivery Networks) à utiliser la dernière version de leurs fichiers hébergés.
Cette technique nécessite l’ajout d’un identifiant unique aux pages ou aux ressources de page que vous souhaitez «décomposer» dans le cache CDN.
Lorsque les développeurs utilisent un ou plusieurs identifiants uniques, des URL supplémentaires à analyser sont créées, généralement des images, des fichiers CSS et JavaScript, mais cela n’est généralement pas grave.
Le plus gros problème survient lorsqu'ils décident d'utiliser des identifiants uniques aléatoires, de mettre à jour fréquemment des pages et des ressources et de laisser les moteurs de recherche explorer toutes les variantes des fichiers.
Voici à quoi cela ressemble.

Vous pouvez détecter ces problèmes dans les journaux de votre serveur et je couvrirai le code pour le faire dans la section suivante.
Mise en cache de pages versionnées avec redimensionnement d'image
Semblable à la suppression du cache, un problème curieux se pose avec les plugins de mise en cache de pages statiques comme ceux développés par une société appelée MageWorx.
Pour l'un de nos clients, leur plug-in Magento enregistrait différentes versions de ressources de page pour chaque modification apportée par le client.
Ce problème était aggravé lorsque le plug-in redimensionnait automatiquement les images en différentes tailles par périphérique pris en charge.
Ce n'était probablement pas un problème quand ils ont initialement développé le plugin, car Google n'essayait pas d'explorer de manière agressive les ressources de la page.
Le problème est que les robots d'exploration des moteurs de recherche analysent désormais également les ressources de la page et analyseront toutes les versions créées par le plug-in de mise en cache.
Nous avions un client dont le taux d'analyse était cent fois supérieur à la taille du site. 70% des demandes d'analyse visaient des images. Vous ne pouvez détecter un problème comme celui-ci qu'en consultant les journaux.
Nous allons générer de fausses requêtes Googlebot pour des images mises en cache au hasard afin de mieux illustrer le problème et ainsi apprendre à identifier le problème.
Voici le code d'initialisation:
Voici la boucle pour générer les fausses entrées du journal.
Ensuite, utilisons pandas et matplotlib pour identifier ce problème.
Ce graphique affiche l'image ci-dessous.
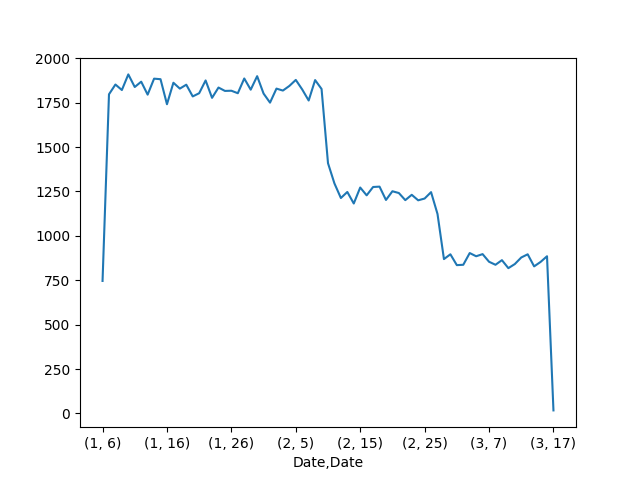

Ce graphique montre les demandes Googlebot par jour. Il est similaire à la fonctionnalité Statistiques d'exploration de l'ancienne console de recherche. Ce rapport a été ce qui nous a incité à creuser plus profondément dans les journaux.
Une fois que vous avez reçu les demandes Googlebot dans un cadre de données Pandas, il est assez facile de localiser le problème.
Voici comment nous pouvons filtrer sur l’un des jours avec le pic d’analyse et les répartir par type de page par extension de fichier.
Longues chaînes et boucles de redirection
Un moyen simple de gaspiller le budget des robots d'exploration est de disposer de très longues chaînes de redirection, voire de boucles. Ils se produisent généralement à cause d'erreurs de codage.
Codons un exemple de chaîne de redirection qui résulte en une boucle afin de mieux les comprendre.
C'est ce qui se produit lorsque vous ouvrez la première URL dans Chrome.
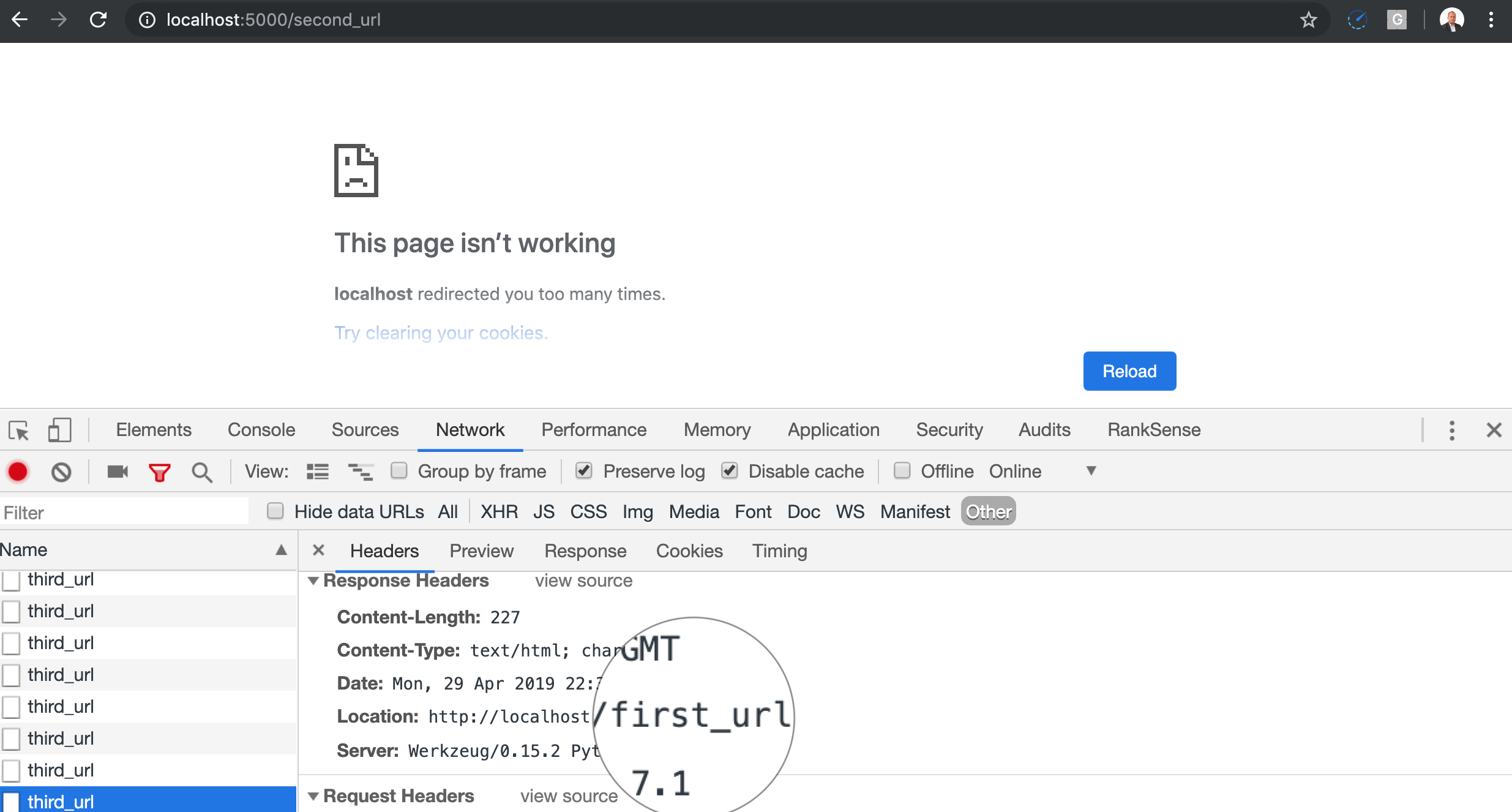
Vous pouvez également voir la chaîne dans le journal de l'application Web.
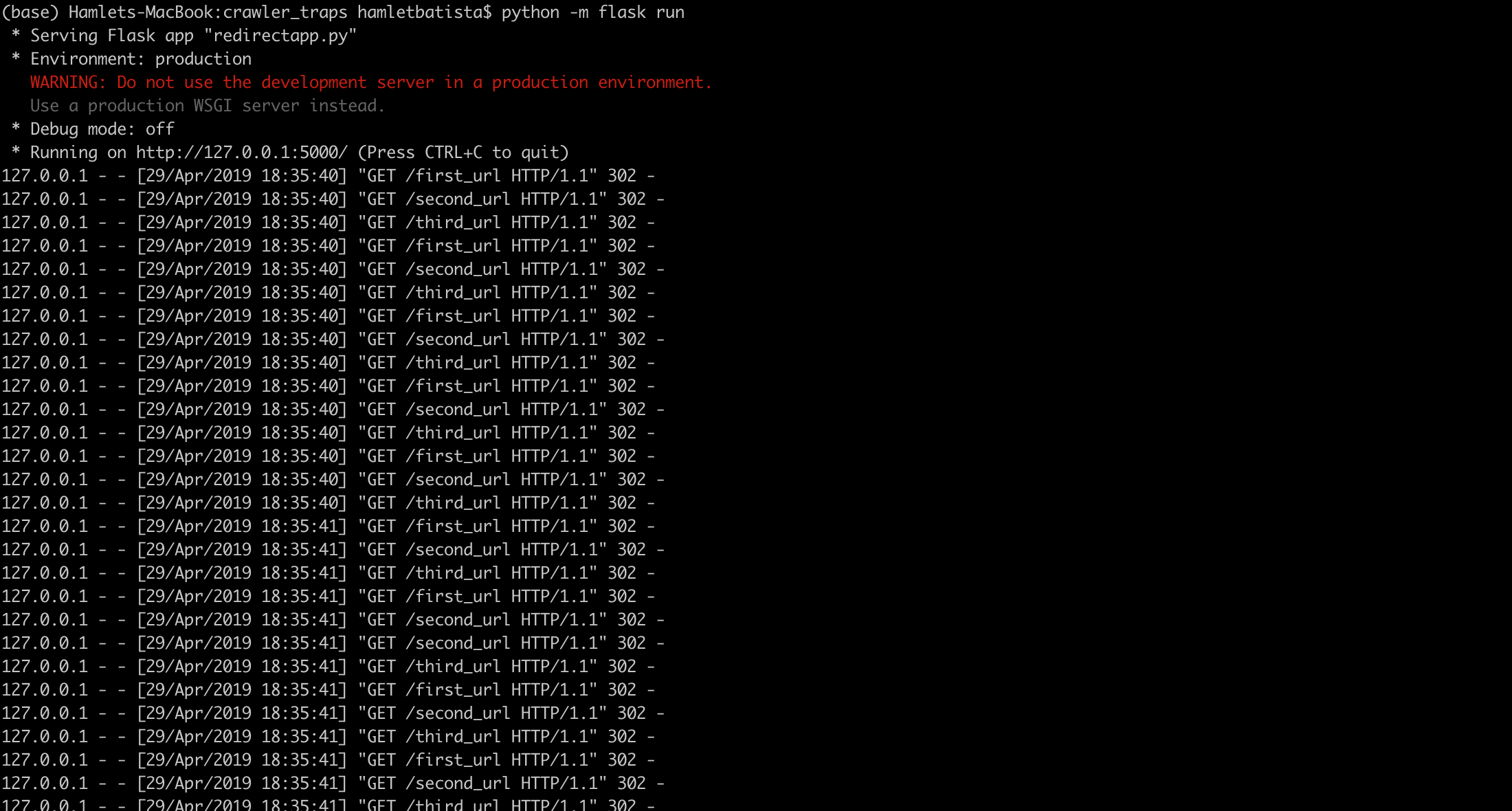
Lorsque vous demandez aux développeurs d'implémenter des règles de réécriture pour:
- Passez de http à https.
- URL minuscules et mixtes.
- Rendre le moteur de recherche URL convivial.
- Etc.
Ils mettent en cascade chaque règle de sorte que chacune d’elles nécessite une redirection distincte au lieu d’une seule, de source à destination.
Les chaînes de redirection sont faciles à détecter, car vous pouvez voir le code ci-dessous.
Ils sont également relativement faciles à corriger une fois que vous avez identifié le code problématique. Toujours rediriger de la source vers la destination finale.
Lien de redirection mobile / de bureau
Un type de redirection intéressant est celui utilisé par certains sites pour aider les utilisateurs à forcer la version mobile ou de bureau du site. Parfois, il utilise un paramètre URL pour indiquer la version du site demandée, ce qui constitue généralement une approche sûre.
Toutefois, les cookies et la détection d’agent utilisateur sont également populaires. C’est à ce moment-là que des boucles peuvent se produire, car les robots du moteur de recherche ne les définissent pas.
Ce code montre comment cela devrait fonctionner correctement.
Celui-ci montre comment cela pourrait fonctionner incorrectement en modifiant les valeurs par défaut pour refléter des hypothèses erronées (dépendance à la présence de cookies HTTP).
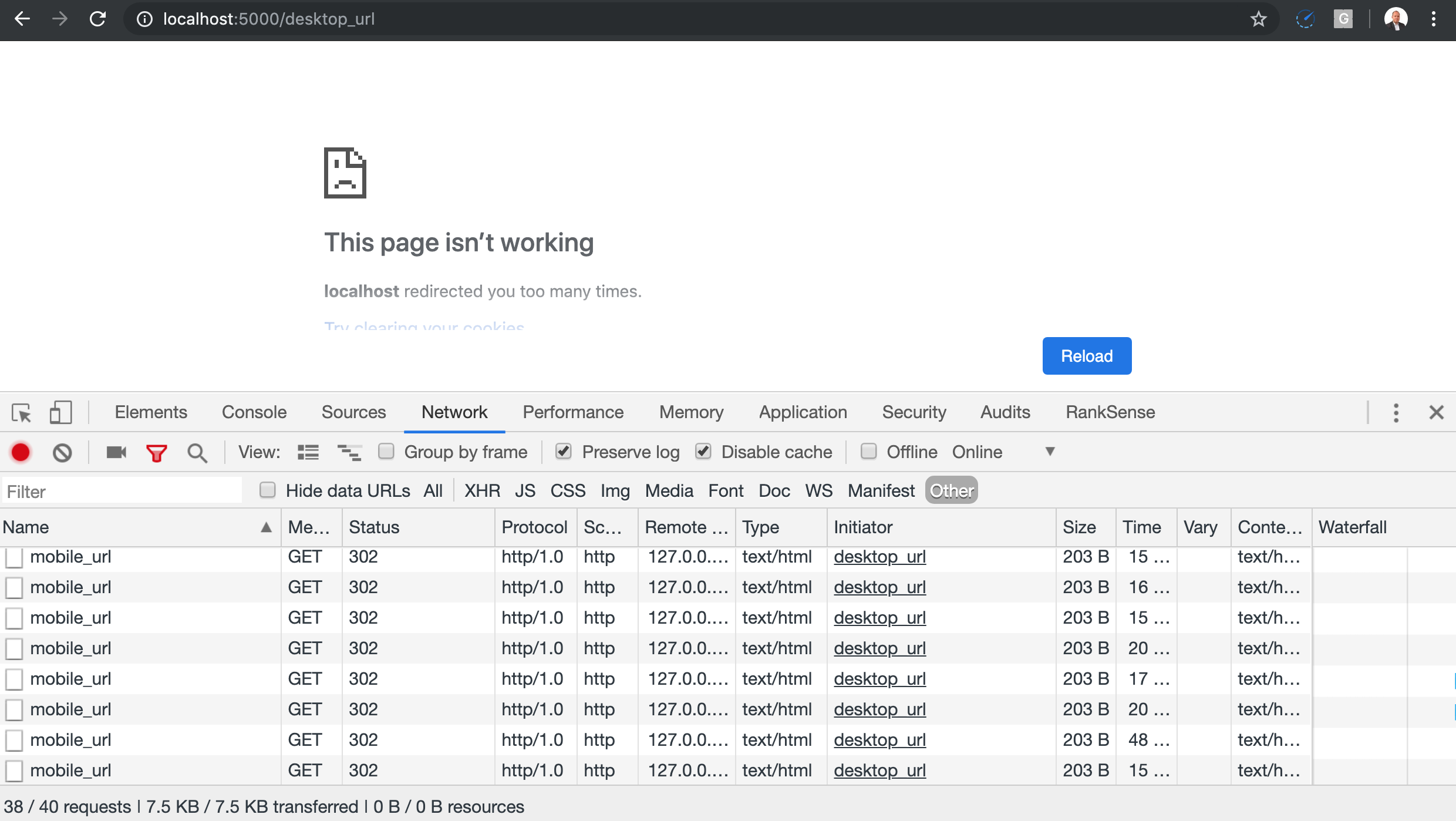
URL de proximité circulaires
Cela nous est arrivé récemment. Il s’agit d’un cas inhabituel, mais j’espère que cela se produira plus souvent à mesure que de plus en plus de services se déplacent derrière des services de proxy tels que Cloudflare.
Vous pouvez avoir des URL soumises à un proxy plusieurs fois de manière à créer une chaîne. Semblable à la façon dont cela se passe avec les redirections.
Vous pouvez considérer les URL mandatées comme des URL redirigées côté serveur. L’URL ne change pas dans le navigateur mais le contenu le fait. Pour suivre les boucles d'URL mandatées, vous devez vérifier les journaux de votre serveur.
Nous avons une application dans Cloudflare qui fait des appels d'API à notre backend pour obtenir des modifications de référencement à apporter. Notre équipe a récemment introduit une erreur qui provoquait la proxy de nos appels d'API, créant ainsi une boucle méchante et difficile à détecter.
Nous avons utilisé le super pratique Logflare app de @chasers consulter nos journaux d’appels d’API en temps réel. Voici à quoi ressemblent les appels réguliers.
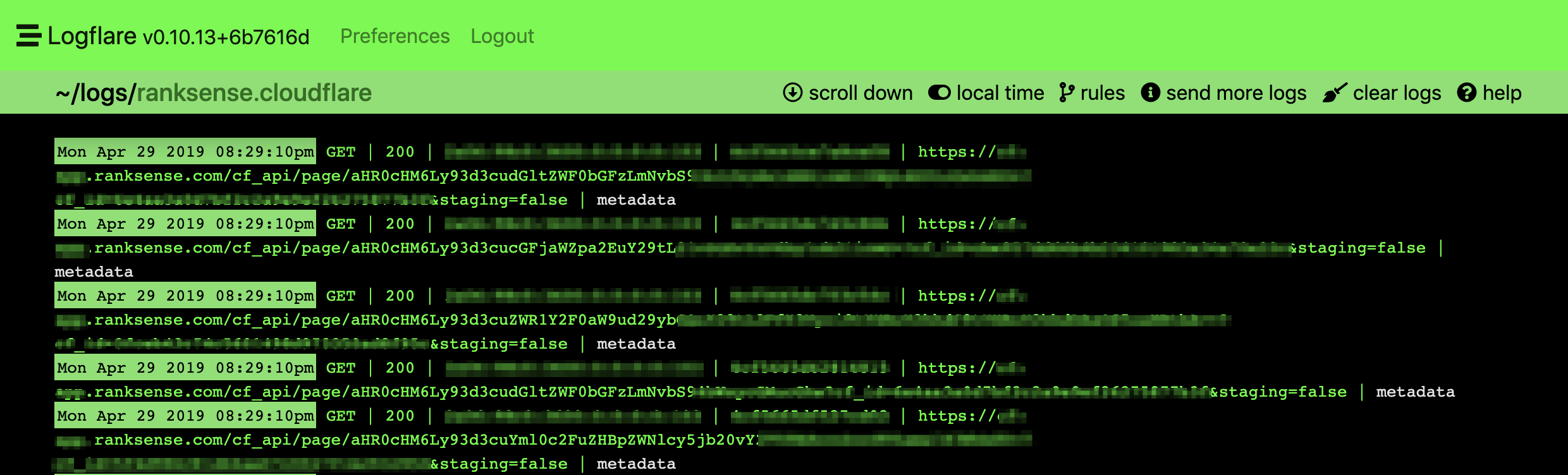
Voici un exemple de circulaire / récursif. C'est une demande massive. J'ai trouvé des centaines de demandes chaînées lorsque j'ai décodé le texte.
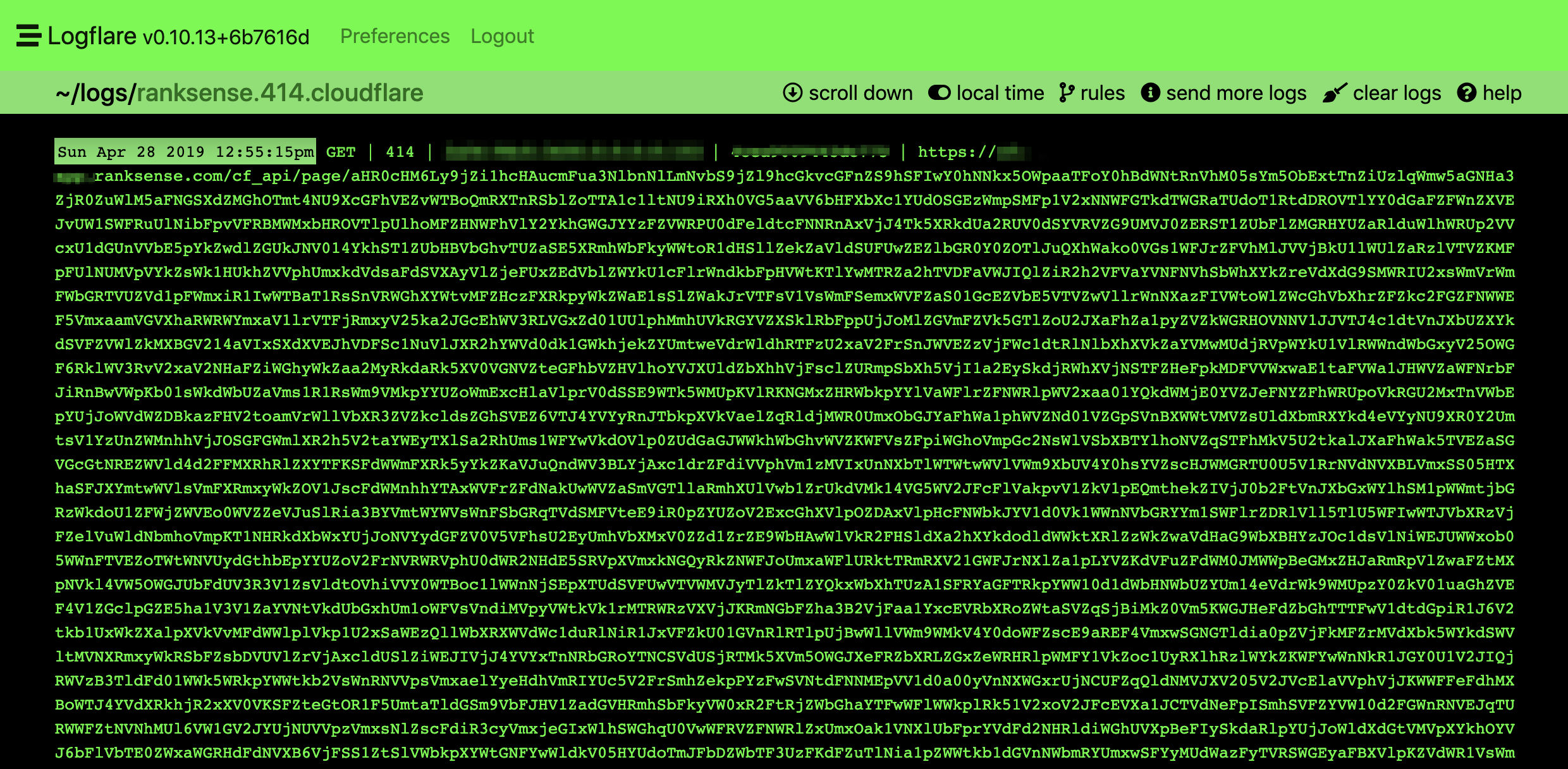
Nous pouvons utiliser le même truc que nous avons utilisé pour détecter les liens relatifs défectueux. Nous pouvons filtrer par code d'état 414 ou même la longueur de la demande.
La plupart des demandes ne doivent pas dépasser 2 049 caractères. Vous pouvez vous référer au code que nous avons utilisé pour les redirections défectueuses.
URL magiques + texte aléatoire
Un autre exemple est celui où les URL incluent du texte facultatif et nécessitent uniquement un ID pour servir le contenu.
En règle générale, ce n'est pas grave, sauf lorsque les URL peuvent être liées à tout texte aléatoire et incohérent depuis le site.
For example, when the product URL changes name often, search engines need to crawl all the variations.
Here is one example.
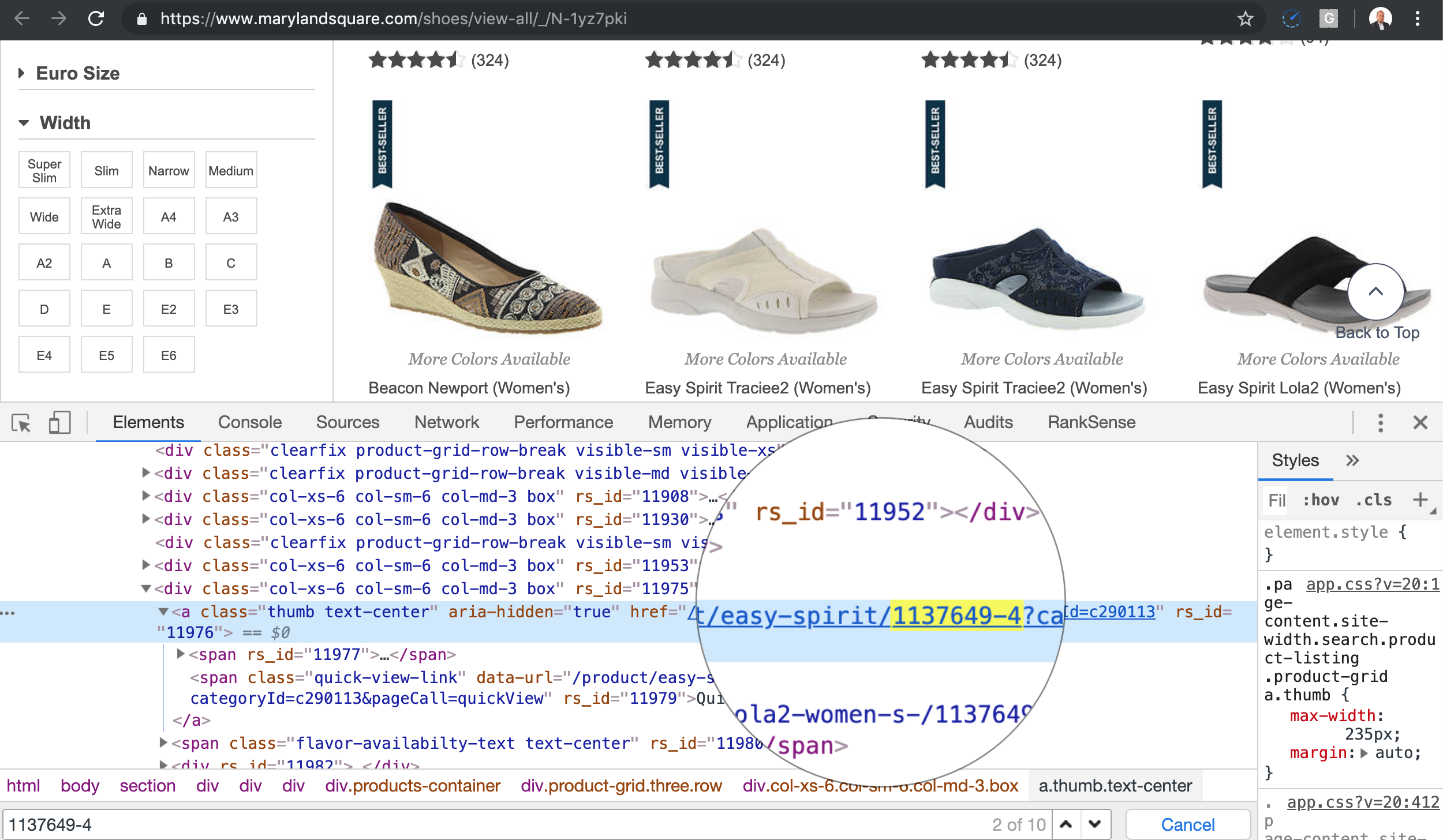
If I follow the link to the product 1137649-4 with a short text as the product description, I get the product page to load.
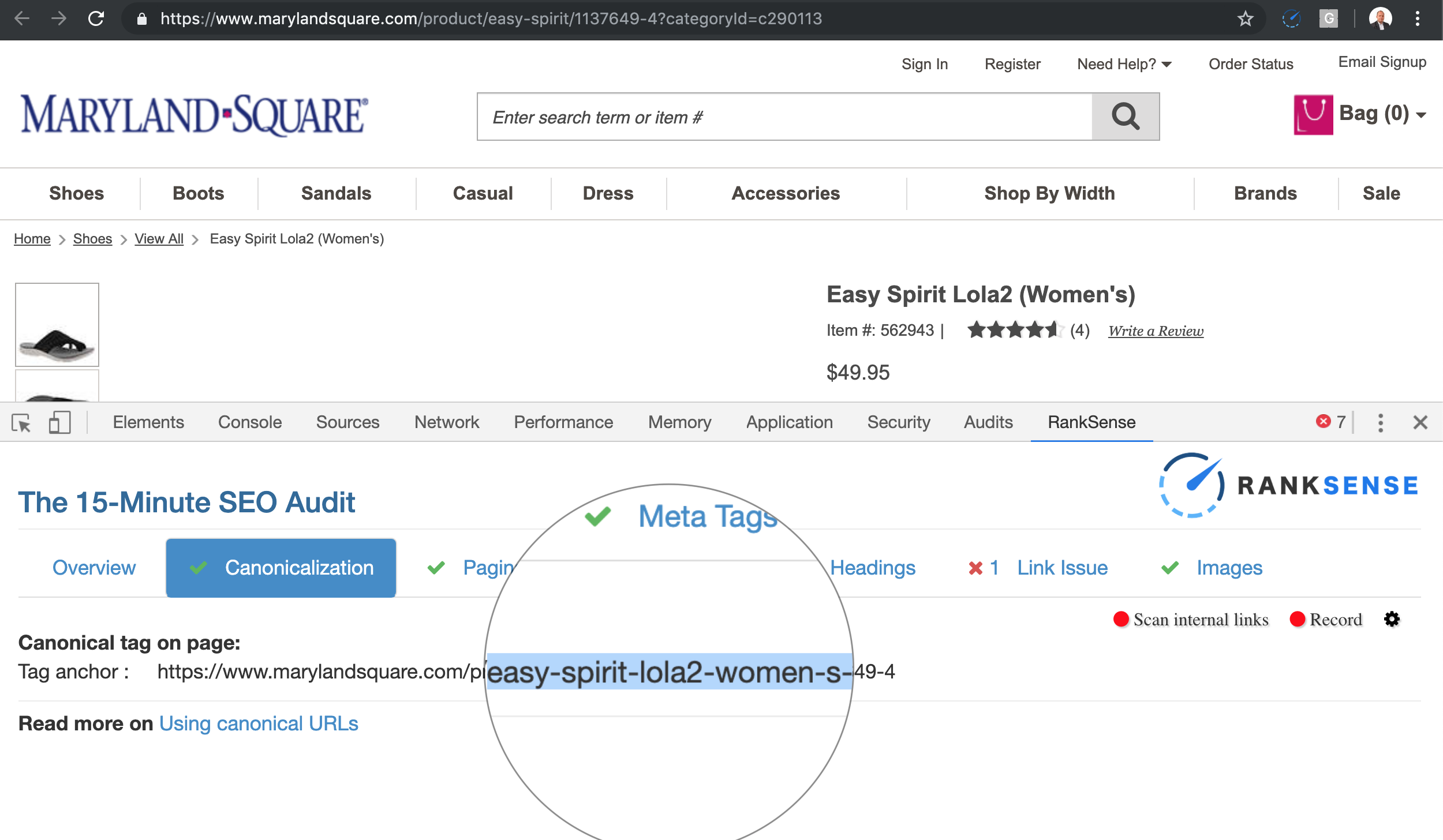
But, you can see the canonical is different than the page I requested.
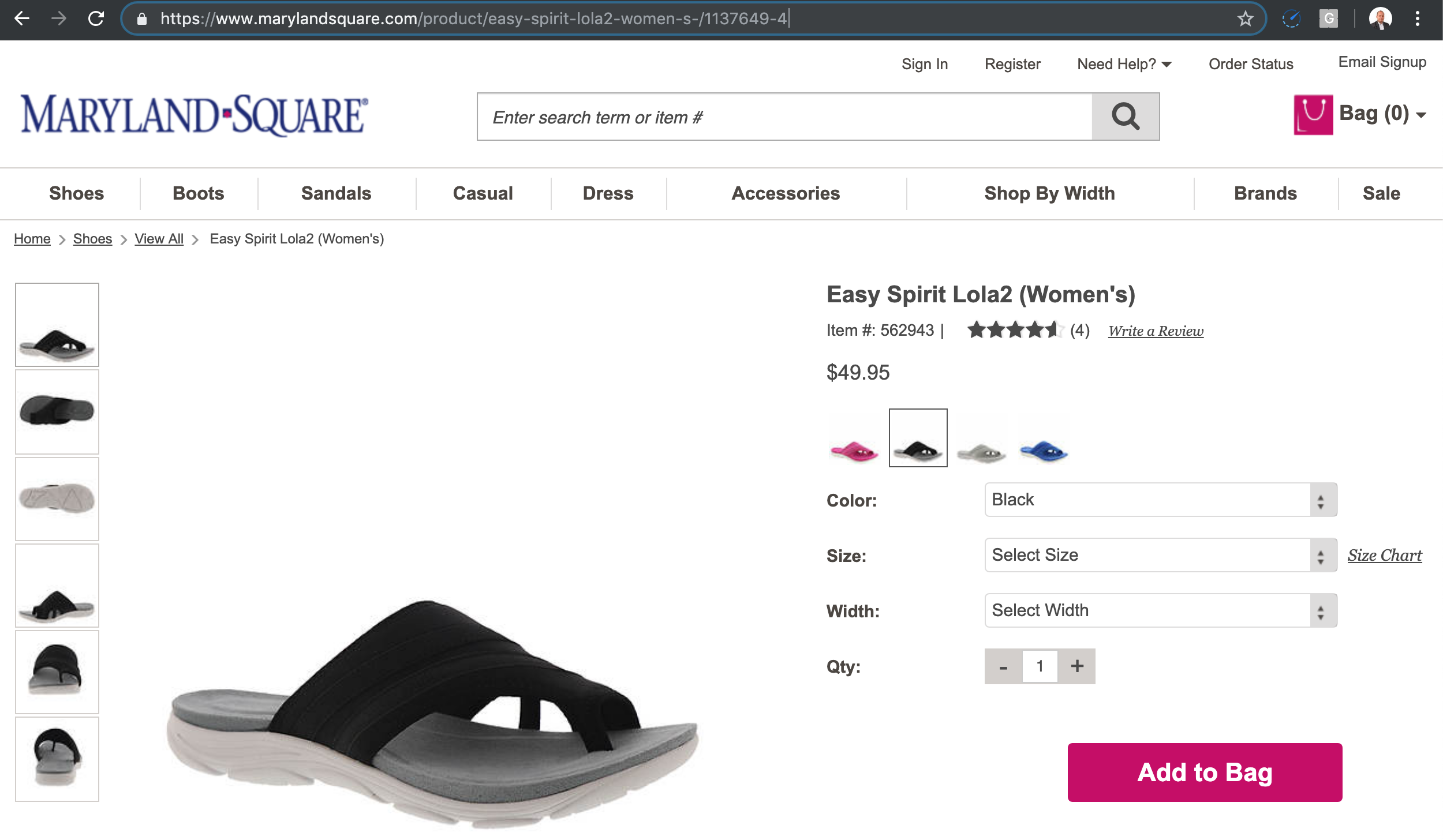
Basically, you can type any text between the product and the product ID, and the same page loads.
The canonicals fix the duplicate content issue, but the crawl space can be big depending on how many times the product name is updated.
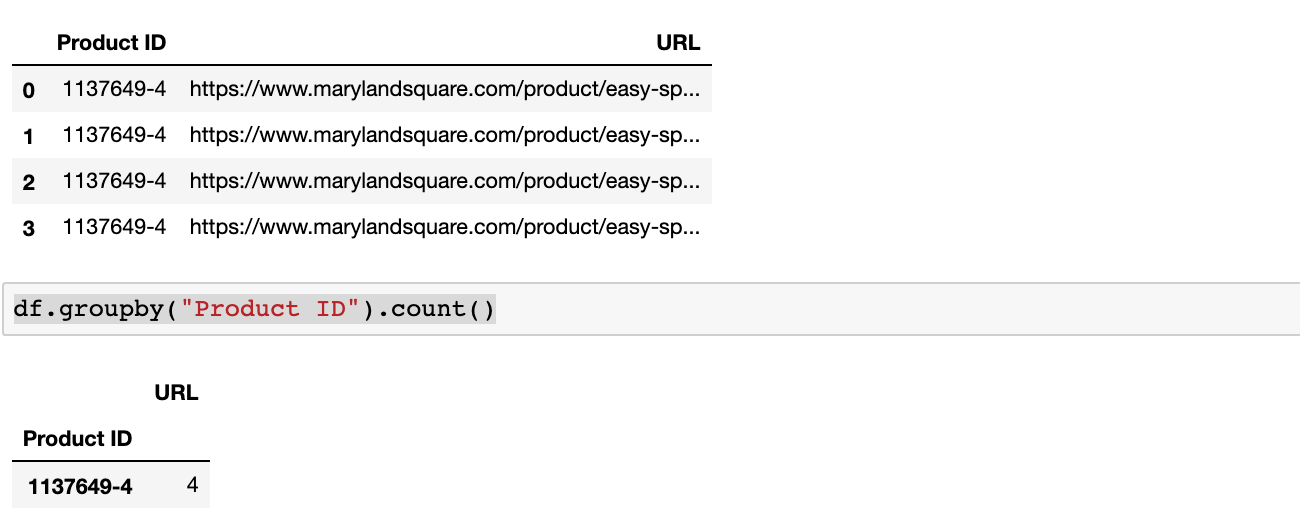
In order to track the impact of this issue, you need to break the URL paths into directories and group the URLs by their product ID. Here is the code to do that.
Here is the example output.
Links to Dynamically Generated Internal Searches
Some on-site search vendors help create “new” keyword based content simply by performing searches with a large number of keywords and formatting the search URLs like regular URLs.
A small number of such URLs is generally not a big deal, but when you combine this with massive keyword lists, you end up with a similar situation as the one I mentioned for the faceted navigation.
Too many URLs leading to mostly the same content.
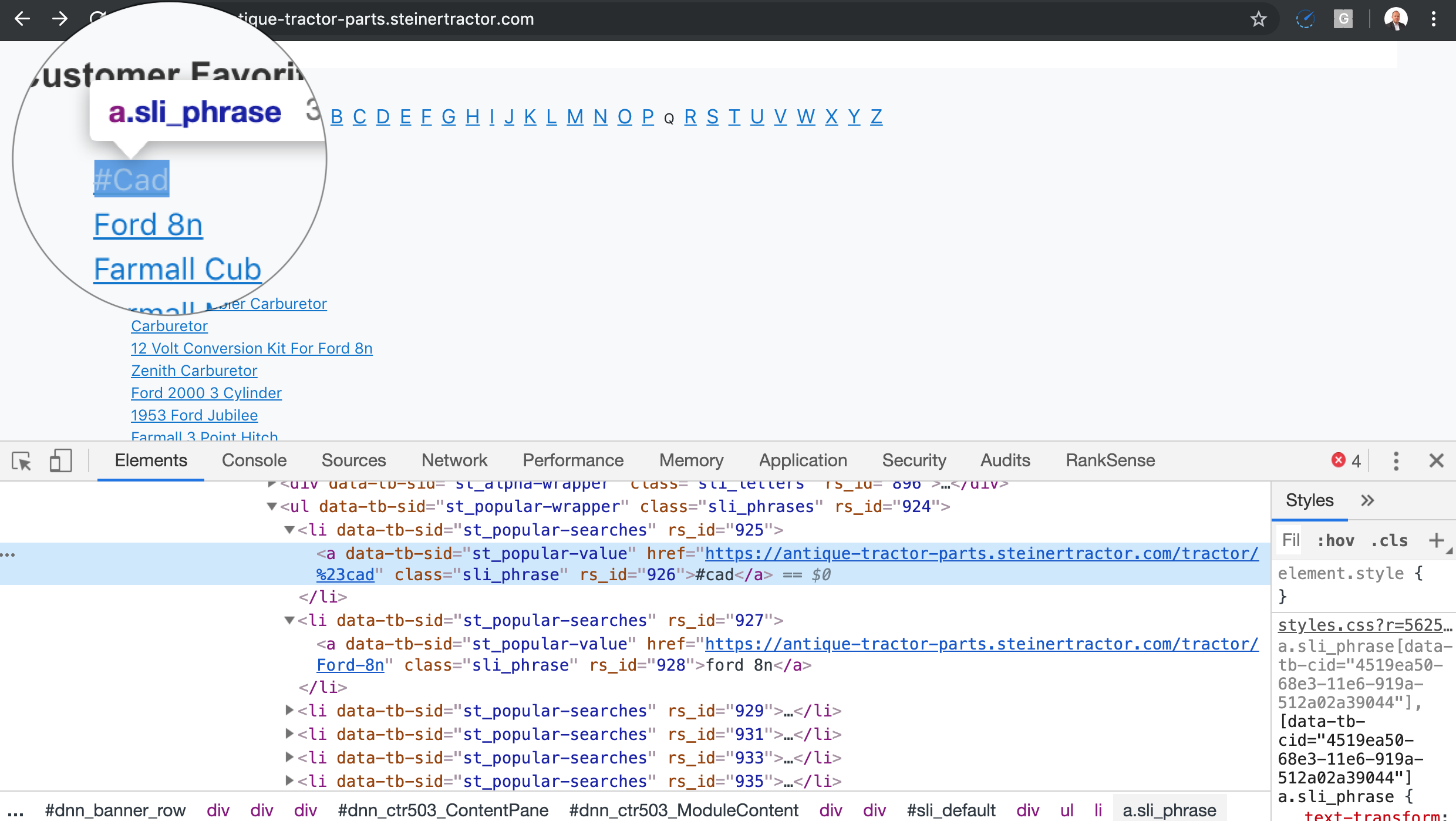
One trick you can use to detect these is to look for the class IDs of the listings and see if they match the ones of the listings when you perform a regular search.
In the example above, I see a class ID “sli_phrase”, which hints the site is using SLI Systems to power their search.
I’ll leave the code to detect this one as an exercise for the reader.
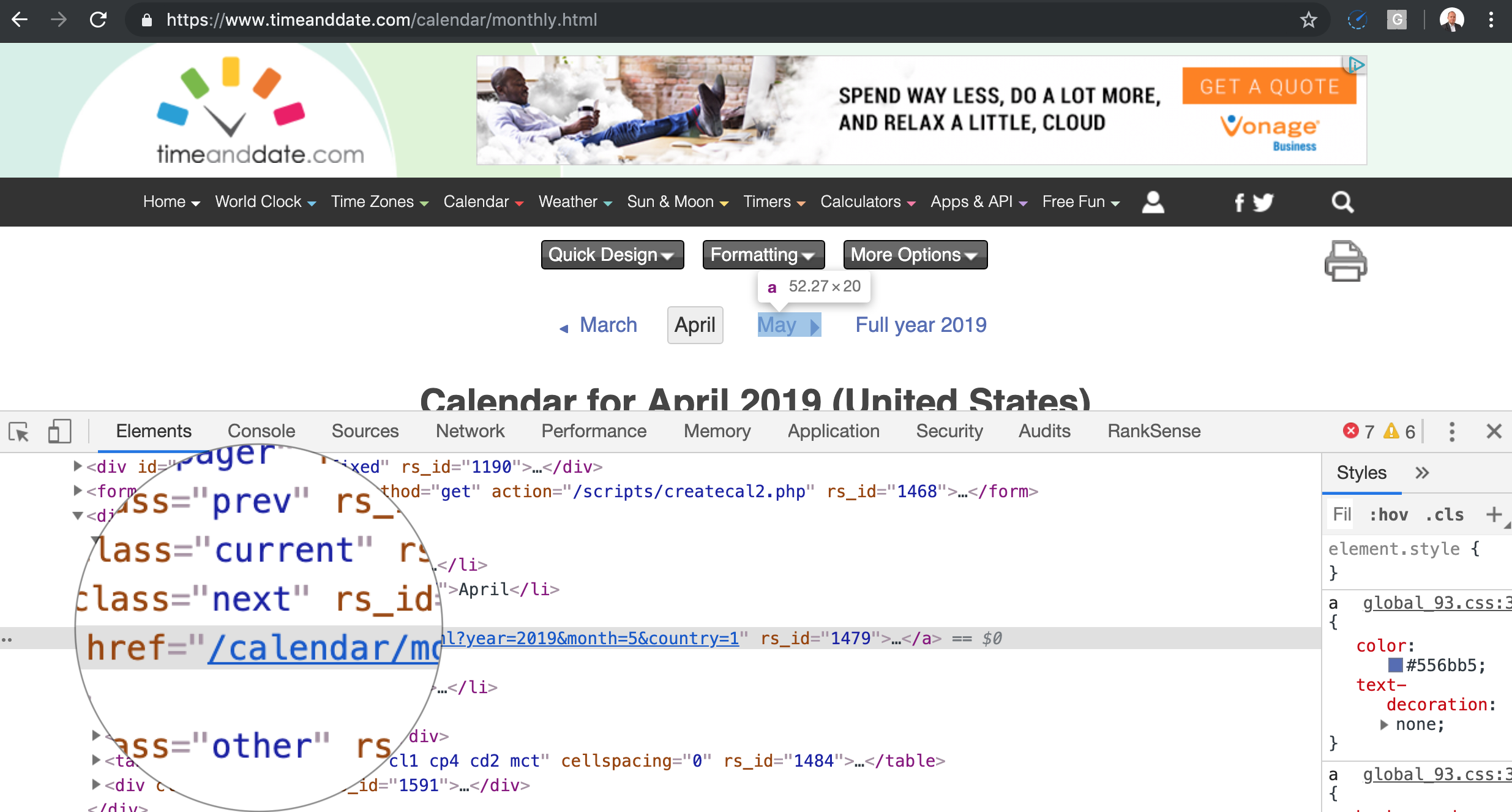
Calendar/Event Links
This is probably the easiest crawler trap to understand.
If you place a calendar on a page, even if it is a JavaScript widget, and you let the search engines crawl the next month links, it will never end for obvious reasons.
Writing generalized code to detect this one automatically is particularly challenging. I’m open to any ideas from the community.
How to Catch Crawler Traps Before Releasing Code to Production
Most modern development teams use a technique called Intégration continue to automate the delivery of high quality code to production.
Automated tests are a key component of continuous integration workflows and the best place to introduce the scripts we put together in this article to catch traps.
The idea is that once a crawler trap is detected, it would halt the production deployment. You can use the same approach and write tests for many other critical SEO problems.
CircleCI is one of the vendors in this space and below you can see the example output from one of our builds.
How to Diagnose Traps After the Fact
At the moment, the most common approach is to catch the crawler traps after the damage is done. You typically run an SEO spider crawl and if it never ends, you likely got a trap.
Check in Google search using operators like site: and if there are way too many pages indexed you have a trap.
You can also check the Google Search Console URL parameters tool for parameters with an excessive number of monitored URLs.
You will only find many of the traps mentioned here in the server logs by looking for repetitive patterns.
You also find traps when you see a large number of duplicate titles or meta descriptions. Another thing to check is a larger number of internal links that pages that should exist on the site.
Resources to Learn More
Here are some resources I used while researching this article:
Plus de ressources:
Crédits d'image
All screenshots taken by author, May 2019