
Est-ce juste moi ou les mots «balises meta robots» et «robots.txt» ressemblent-ils à quelque chose que Schwarzenegger a dit dans «Terminator 2»?
C’est une des raisons pour lesquelles j’ai commencé à travailler dans le domaine du référencement – cela semblait futuriste mais extrêmement technique pour mes compétences à l’époque.
Espérons que cet article rend la configuration de vos balises meta robots et de vos fichiers robots.txt moins nauséabonde. Commençons.
Balises Meta Robots vs Robots.txt
Avant de creuser les bases de ce que sont les balises meta robots et les fichiers robots.txt, il est important de savoir qu’il n’y a pas un côté meilleur que l’autre à utiliser dans le référencement.
Les fichiers Robots.txt indiquent aux robots d’exploration l’ensemble du site.
Alors que les balises meta robots entrent dans le vif du sujet d’une page spécifique.
Je préfère utiliser des balises meta robots pour de nombreuses choses que d’autres professionnels du référencement peuvent simplement utiliser la simplicité du fichier robots.txt.
Il n’y a pas de réponse juste ou fausse. C’est une préférence personnelle basée sur votre expérience.
Qu’est-ce que Robots.txt?
Un fichier robots.txt indique aux robots d’exploration ce qui doit être analysé.
Cela fait partie du protocole d’exclusion des robots (REP).
Googlebot est un exemple de robot d’exploration.
Google déploie Googlebot pour explorer des sites Web et enregistrer des informations sur ce site pour comprendre comment classer le site dans les résultats de recherche de Google.
Vous pouvez trouver le fichier robots.txt de n’importe quel site en ajoutant /robots.txt après l’adresse Web comme ceci:
www.mywebsite.com/robots.txt
Voici à quoi ressemble un fichier de base, frais, robots.txt:
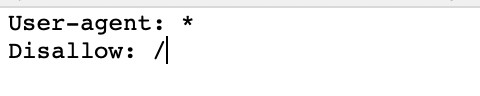

L’astérisque * après user-agent indique aux robots d’exploration que le fichier robots.txt est destiné à tous les robots qui arrivent sur le site.
La barre oblique / après «Interdire» indique au robot de ne pas aller sur les pages du site.
Voici un exemple du fichier robots.txt de Moz.


Vous pouvez voir qu’ils indiquent aux robots les pages à analyser à l’aide des agents utilisateurs et des directives. J’y plongerai un peu plus tard.
Pourquoi Robots.txt est-il important?
Je ne peux pas dire combien de clients viennent me voir après une migration de site Web ou le lancement d’un nouveau site Web et me demandent: pourquoi mon site ne se classe-t-il pas après des mois de travail?
Je dirais que 60% de la raison est que le fichier robots.txt n’a pas été mis à jour correctement.
Cela signifie que votre fichier robots.txt ressemble toujours à ceci:
Cela bloquera tous les robots d’exploration Web qui visitent votre site.
Une autre raison pour laquelle le fichier robots.txt est important est que Google a ce qu’on appelle un budget d’exploration.
Google déclare:
« Googlebot est conçu pour être un bon citoyen du Web. L’analyse est sa principale priorité, tout en s’assurant qu’elle ne dégrade pas l’expérience des utilisateurs visitant le site. Nous appelons cela la «limite de taux d’exploration», qui limite le taux de récupération maximal pour un site donné.
En termes simples, cela représente le nombre de connexions parallèles simultanées que Googlebot peut utiliser pour explorer le site, ainsi que le temps qu’il faut attendre entre les récupérations. «
Donc, si vous avez un gros site avec des pages de mauvaise qualité que vous ne voulez pas que Google explore, vous pouvez dire à Google de les « interdire » dans votre fichier robots.txt.
Cela libérerait votre budget d’exploration pour explorer uniquement les pages de haute qualité pour lesquelles vous souhaitez que Google vous classe.
Il n’y a pas encore de règles strictes pour les fichiers robots.txt… pour le moment.
Google annoncé une proposition en juillet 2019 pour commencer à mettre en œuvre certaines normes, mais pour l’instant, je suis les meilleures pratiques que j’ai faites au cours des dernières années.
Bases de Robots.txt
Comment utiliser Robots.txt
L’utilisation de robots.txt est vitale pour le succès du référencement.
Mais, ne pas comprendre comment cela fonctionne peut vous laisser vous gratter la tête pour savoir pourquoi vous ne vous situez pas.
Les moteurs de recherche exploreront et indexeront votre site en fonction de ce que vous leur dites dans le fichier robots.txt à l’aide de directives et d’expressions.
Ci-dessous sont directives robots.txt communes tu devrais savoir:
Agent utilisateur: * – Il s’agit de la première ligne de votre fichier robots.txt pour expliquer aux robots d’exploration les règles de ce que vous souhaitez qu’ils explorent sur votre site. L’astérisque informe toutes les araignées.
Agent utilisateur: Googlebot – Cela indique uniquement ce que vous souhaitez que l’araignée de Google explore.
Interdire: / – Cela indique à tous les robots d’exploration de ne pas explorer l’intégralité de votre site.
Refuser: – Cela indique à tous les robots d’exploration d’explorer l’intégralité de votre site.
Interdire: / mise en scène / – Cela indique à tous les robots d’exploration d’ignorer votre site de transfert.
Interdire: / ebooks / * .pdf – Cela indique aux robots d’exploration d’ignorer tous vos formats PDF, ce qui peut entraîner des problèmes de contenu en double.
Agent utilisateur: Googlebot
Interdire: / images / – Cela indique uniquement au robot d’exploration Googlebot d’ignorer toutes les images de votre site.
* – Ceci est considéré comme un caractère générique qui représente n’importe quelle séquence de caractères.
$ – Ceci est utilisé pour faire correspondre la fin de l’URL.
Pour créer un fichier robots.txt, j’utilise Yoast pour WordPress. Il s’intègre déjà à d’autres fonctionnalités de référencement sur mes sites.
Mais avant de commencer créez votre fichier robots.txt, voici quelques notions de base à retenir:
- Formatez correctement votre fichier robots.txt. SEMrush fait un grand exemple de la façon dont un robots.txt doit être correctement formaté. Vous voyez que la structure suit ce modèle: User-agent → Interdire → Autoriser → Hôte → Plan du site. Cela permet aux moteurs de recherche d’accéder aux catégories et aux pages Web dans le bon ordre.


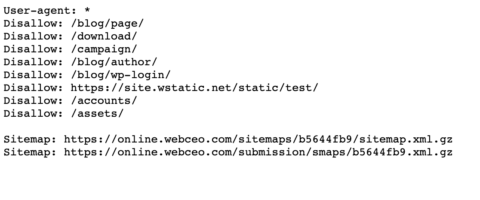
- Assurez-vous que chaque URL que vous souhaitez «Autoriser:» ou «Interdire:» est placée sur une ligne distincte comme Best Buy fait ci-dessous. Et, ne séparez pas avec l’espacement.

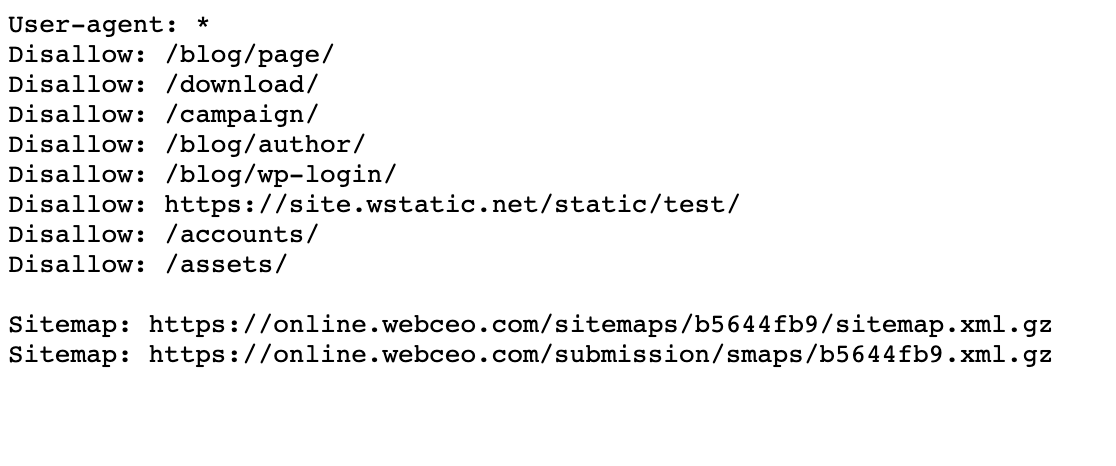
- Utilisez toujours des minuscules pour nommer votre robots.txt comme le fait WebCEO.

- N’utilisez pas de caractères spéciaux sauf * et $. Les autres personnages ne sont pas reconnus.
- Créez des fichiers robots.txt distincts pour différents sous-domaines. Par exemple, «hubspot.com» et «blog.hubspot.com» ont des fichiers individuels et tous deux ont des fichiers robots.txt différents.
- Utilisez # pour laisser des commentaires dans votre fichier robots.txt. Les robots ne respectent pas les lignes avec le caractère # comme je l’ai fait ici avec ce fichier robots.txt.
- Si une page n’est pas autorisée dans les fichiers robots.txt, l’équité du lien ne passera pas.
- N’utilisez jamais le fichier robots.txt pour protéger ou bloquer des données sensibles.
Que cacher avec Robots.txt
Les fichiers Robots.txt sont souvent utilisés pour exclure des répertoires, catégories ou pages spécifiques des SERP.
Vous pouvez exclure en utilisant la directive «interdire».
Voici quelques pages courantes que je cache à l’aide d’un fichier robots.txt:
- Pages avec du contenu en double (souvent du contenu imprimable)
- Pages de pagination
- Pages produits et services dynamiques
- Pages de compte
- Pages d’administration
- Panier
- Chats
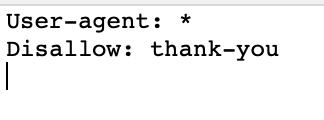
- Pages de remerciements
C’est très utile pour les sites de commerce électronique utilisant des paramètres comme ceux de Macy.

Et, vous pouvez voir ici comment j’ai refusé une page de remerciement.


Il est important de savoir que tous les robots ne suivront pas votre fichier robots.txt.
Les mauvais bots peuvent ignorer complètement votre fichier robots.txt, assurez-vous donc que vous ne conservez pas de données sensibles sur les pages bloquées.
Erreurs courantes de Robots.txt
Après avoir géré des fichiers robots.txt pendant plus de 10 ans maintenant, voici quelques-unes des erreurs courantes que je vois:
Erreur n ° 1: le nom du fichier contient des majuscules
Le seul nom de fichier possible est robots.txt, ni Robots.txt ou ROBOTS.TXT.
Restez en minuscules, toujours en matière de référencement.
Erreur # 2: ne pas placer le fichier Robots.Txt dans le répertoire principal
Si vous voulez que votre fichier robots.txt soit trouvé, vous devez le placer dans le répertoire principal de votre site.
Faux
www.mysite.com/tshirts/robots.txt
Correct
www.mysite.com/robots.txt
Erreur n ° 3: agent utilisateur mal formaté
Faux
Interdire: Googlebot
Correct
Agent utilisateur: Googlebot
Interdire: /
Erreur n ° 4: mentionner plusieurs catalogues sur une seule ligne «Interdire»
Faux
Interdire: / css / / cgi-bin / / images /
Correct
Interdire: / css /
Interdire: / cgi-bin /
Interdire: / images /
Erreur # 5: ligne vide dans ‘User-Agent’
Faux
Agent utilisateur:
Refuser:
Correct
Agent utilisateur: *
Refuser:
Erreur n ° 6: sites Web miroir et URL dans la directive hôte
Soyez prudent lorsque vous mentionnez les directives «hôte», afin que les moteurs de recherche vous comprennent correctement:
Faux
Agent utilisateur: Googlebot
Interdire: / cgi-bin
Correct
Agent utilisateur: Googlebot
Interdire: / cgi-bin
Hébergeur: www.site.com
Si votre site possède https, l’option correcte est:
Agent utilisateur: Googlebot
Interdire: / cgi-bin
Hébergeur: https://www.site.com
Erreur n ° 7: répertorier tous les fichiers du répertoire
Faux
Agent utilisateur: *
Interdire: /pajamas/flannel.html
Interdire: /pajamas/corduroy.html
Interdire: /pajamas/cashmere.html
Correct
Agent utilisateur: *
Interdire: / pyjamas /
Interdire: / chemises /
Erreur n ° 8: aucune instruction d’interdiction
Les instructions d’interdiction sont nécessaires pour que les robots des moteurs de recherche comprennent votre intention.
Faux
Agent utilisateur: Googlebot
Hébergeur: www.mysite.com
Correct
Agent utilisateur: Googlebot
Refuser:
Hébergeur: www.mysite.com
Erreur n ° 9: blocage de l’ensemble de votre site
Faux
Agent utilisateur: Googlebot
Interdire: /
Correct
Agent utilisateur: Googlebot
Refuser:
Erreur n ° 10: utilisation de différentes directives dans la section *
Faux
Agent utilisateur: *
Interdire: / css /
Hébergeur: www.example.com
Correct
Agent utilisateur: *
Interdire: / css /
Erreur # 11: en-tête HTTP incorrect
Faux
Type de contenu: texte / html
Correct
Type de contenu: texte / simple
Erreur # 12: pas de plan du site
Placez toujours vos sitemaps au bas de votre fichier robots.txt.
Faux


Correct


Erreur # 13: Utiliser Noindex
Google a annoncé en 2019 qu’il ne reconnaissent plus la directive noindex utilisé dans les fichiers robots.txt.
Alors, utilisez plutôt les balises meta robots dont je parle ci-dessous.
Faux


Correct

Erreur n ° 14: interdiction d’une page dans le fichier Robots.Txt, mais toujours en y liant
Si vous interdisez une page dans le fichier robots.txt, Google continuera d’explorer la page si vous avez des liens internes pointant vers elle.
Vous devez supprimer ces liens pour que les araignées cessent d’explorer complètement cette page.
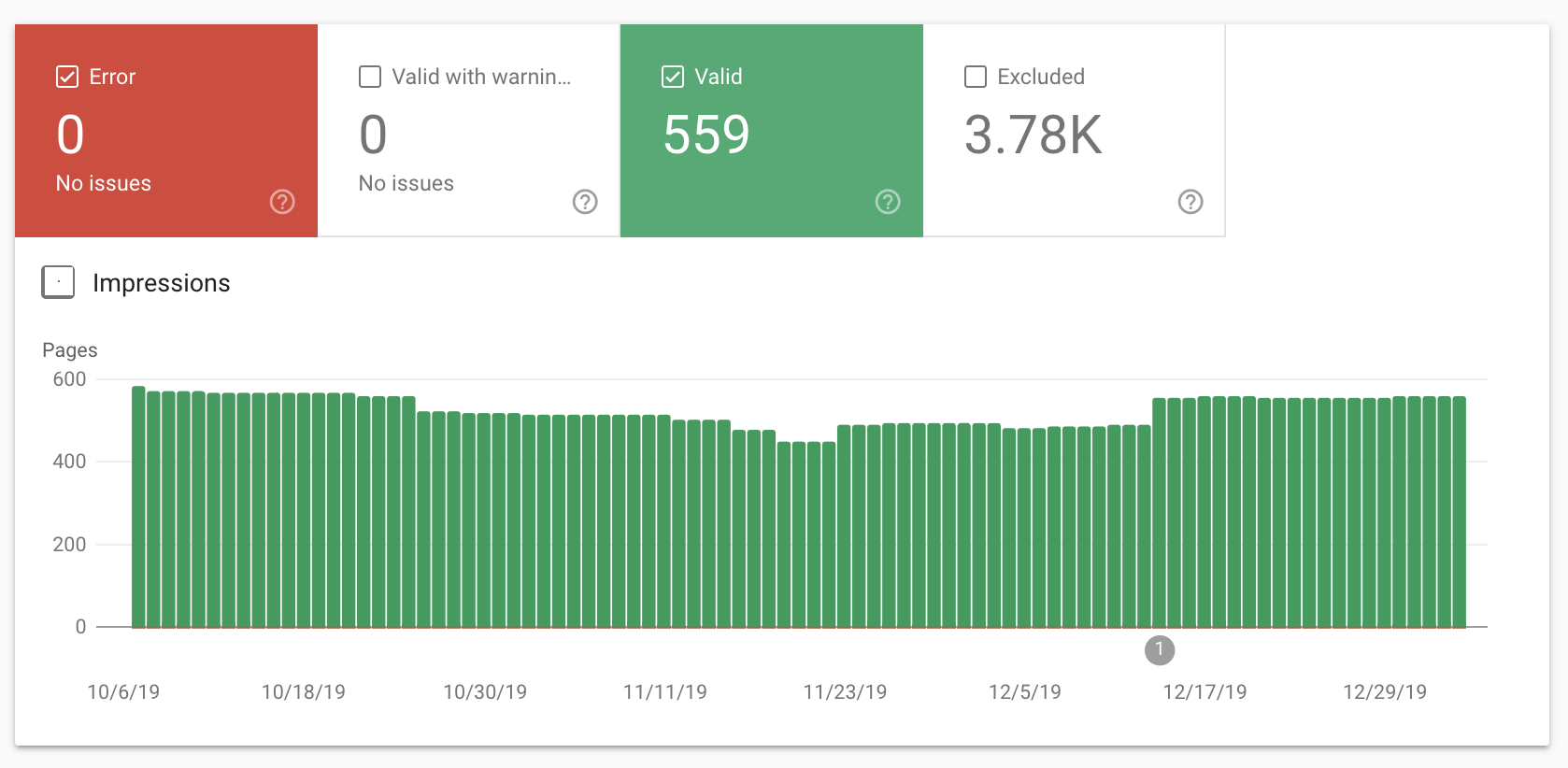
En cas de doute, vous pouvez vérifier quelles pages sont indexées dans votre rapport de couverture de Google Search Console.
Vous devriez voir quelque chose comme ceci:
Et tu peux utiliser l’outil de test robots.txt de Google.
Cependant, si vous utilisez l’outil de test adapté aux mobiles de Google, il ne suit pas vos règles dans le fichier robots.txt.

Que sont les balises Meta Robots?
Les balises meta robots (également appelées directives meta robots) sont des extraits de code HTML qui indiquent aux robots des moteurs de recherche comment explorer et indexer les pages de votre site Web.
Les balises meta robots sont ajoutées au
section d’une page Web.Voici un exemple:
Les balises meta robots sont composées de deux parties.
La première partie de la balise est name = ’’ ’.
C’est là que vous identifiez l’agent utilisateur. Par exemple, « Googlebot ».
La deuxième partie de la balise est content = ’’. C’est là que vous dites aux bots ce que vous voulez qu’ils fassent.
Types de balises Meta Robots
Les balises Meta robots ont deux types de balises:
- Balise Meta robots.
- X-robots-tag.
Type 1: balise Meta Robots
Les balises Meta robots sont couramment utilisées par les spécialistes du marketing SEO.
Il vous permet de dire aux agents utilisateurs (pensez à Googlebot) d’explorer des zones spécifiques.
Voici un exemple:
Cette balise meta robots indique au robot d’exploration de Google, Googlebot, de ne pas indexer la page dans les moteurs de recherche et de ne suivre aucun backlink.
Ainsi, cette page ne ferait pas partie des SERPs.
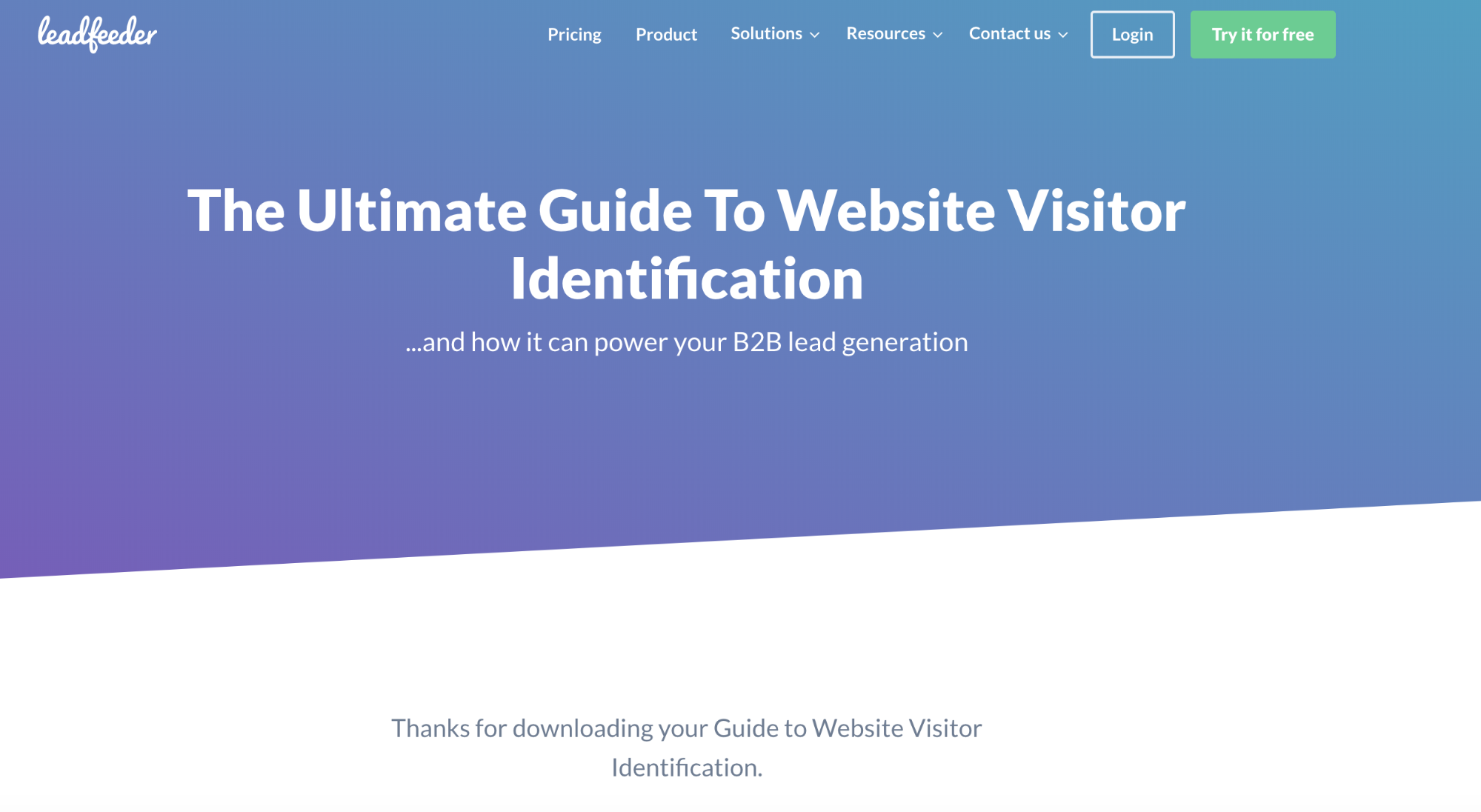
J’utiliserais cette balise meta robots pour une page de remerciement.
Voici un exemple d’une page de remerciement après avoir téléchargé un ebook.

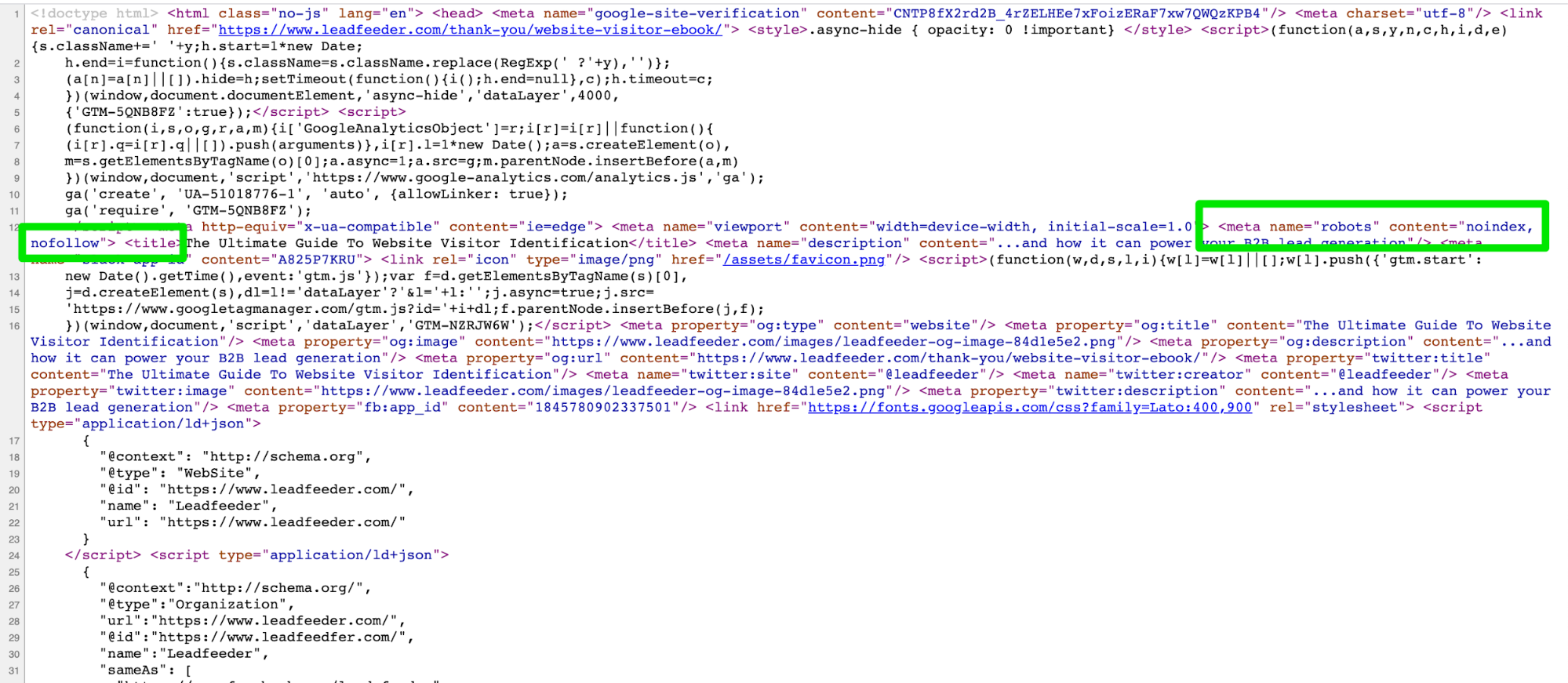
Maintenant, si vous regardez le code backend, vous verrez qu’il dit noindex et nofollow.

Si vous utilisez différentes directives de balises meta robots pour différents agents utilisateurs de recherche, vous devrez utiliser des balises distinctes pour chaque bot.
Il est essentiel de ne pas placer les balises meta robots en dehors du
section. Glenn Gabe vous montre pourquoi cette étude de cas.Type 2: X-robots-tag
le x-robots-tag vous permet de faire la même chose que les balises meta robots mais dans les en-têtes d’une réponse HTTP.
Essentiellement, il vous offre plus de fonctionnalités que les balises meta robots.
Cependant, vous aurez besoin d’accéder aux fichiers .php, .htaccess ou serveur.
Par exemple, si vous souhaitez bloquer une image ou une vidéo, mais pas la page entière, vous utiliserez plutôt x-robots-tag.
Paramètres de balise Meta Robots
Il existe de nombreuses façons d’utiliser les directives de balise meta robots dans le code. Mais, tout d’abord, vous devez comprendre ce que sont ces directives et ce qu’elles font.
Voici une ventilation des directives de balises meta robots:
- tout – Aucune limitation pour l’indexation et le contenu. Cette directive est utilisée par défaut. Cela n’a aucun impact sur le travail des moteurs de recherche. Je l’ai utilisé comme raccourci pour l’index, suivez.
- indice – Autorisez les moteurs de recherche à indexer cette page dans leurs résultats de recherche. C’est un défaut. Vous n’avez pas besoin d’ajouter ceci à vos pages.
- noindex – Supprime la page de l’index des moteurs de recherche et des résultats de recherche. Cela signifie que les chercheurs ne trouveront pas votre site ni ne cliqueront dessus.
- suivre – Permet aux moteurs de recherche de suivre les backlinks internes et externes sur cette page.
- pas de suivi – Ne permettez pas de suivre les backlinks internes et externes. Cela signifie que ces liens ne transmettront pas l’équité des liens.
- aucun – Identique à noindex et aux balises META nofollow.
- noarchive – N’affichez pas le lien «Copie enregistrée» dans les SERPs.
- nosnippet – N’affichez pas la version de description étendue de cette page dans les SERP.
- notranslate – Ne proposez pas la traduction de cette page dans les SERPs.
- noimageindex – N’indexez pas les images sur la page.
- indisponible_après: [RFC-850 date/time] – Ne pas afficher cette page dans les SERPs après la date / heure spécifiée. Utilisez le format RFC 850.
- max-snippet – Établit un nombre maximum pour le nombre de caractères dans la méta description.
- max-video-preview – Établit le nombre de secondes de prévisualisation d’une vidéo.
- max-image-preview – Établit une taille maximale pour l’aperçu de l’image.
Parfois, différents moteurs de recherche acceptent différents paramètres de méta-balise. Voici une ventilation:
| Valeur | Bing | Yandex | |
| indice | Oui | Oui | Oui |
| noindex | Oui | Oui | Oui |
| aucun | Oui | Doute | Oui |
| noimageindex | Oui | Non | Non |
| suivre | Oui | Doute | Oui |
| pas de suivi | Oui | Oui | Oui |
| noarchive | Oui | Oui | Oui |
| nosnippet | Oui | Non | Non |
| notranslate | Oui | Non | Non |
| indisponible_après | Oui | Non | Non |
Comment utiliser les balises Meta Robots
Si vous utilisez un site Web WordPress, il existe de nombreuses options de plug-in pour personnaliser vos balises meta robots.
Je préfère utiliser Yoast. Il s’agit d’un plugin SEO tout-en-un pour WordPress qui offre de nombreuses fonctionnalités.
Mais il y a aussi Gestionnaire de balises méta plugin et Méta-tags GA brancher.
Utilisateurs de Joomla, je recommande EFSEO et Tag Meta.
Peu importe sur quoi votre site est construit, voici trois conseils pour utiliser les balises meta robots:
- Gardez-le sensible à la casse. Les moteurs de recherche reconnaissent les attributs, les valeurs et les paramètres en majuscules et en minuscules. Je vous recommande de vous tenir en minuscules pour améliorer la lisibilité du code. De plus, si vous êtes un spécialiste du marketing SEO, il est préférable de prendre l’habitude d’utiliser des minuscules.
- Évitez les multiples Mots clés. L’utilisation de plusieurs balises META provoquera des conflits dans le code. Utilisez plusieurs valeurs dans votre tag, comme ceci: .
- N’utilisez pas de balises META conflictuelles pour éviter les erreurs d’indexation. Par exemple, si vous avez plusieurs lignes de code avec des balises META comme celle-ci et ça , seul le «nofollow» sera pris en compte. En effet, les robots accordent la priorité aux valeurs restrictives.
Les balises Robots.txt et Meta Robots fonctionnent ensemble
L’une des plus grosses erreurs que je constate lorsque je travaille sur les sites Web de mon client est que le fichier robots.txt ne correspond pas à ce que vous avez indiqué dans les balises meta robots.
Par exemple, le fichier robots.txt masque la page de l’indexation, mais les balises meta robots font le contraire.
Vous vous souvenez de l’exemple de Leadfeeder que j’ai montré ci-dessus?
Vous remarquerez donc que cette page de remerciement est interdit dans le fichier robots.txt et en utilisant les balises meta robots de noindex, nofollow.
D’après mon expérience, Google a donné la priorité à ce qui est interdit par le fichier robots.txt.
Mais, vous pouvez éliminer la non-conformité entre les balises meta robots et robots.txt en indiquant clairement aux moteurs de recherche quelles pages doivent être indexées et lesquelles ne doivent pas l’être.
Dernières pensées
Si vous vous souvenez encore de l’époque de l’achat d’un film Blockbuster dans un centre commercial, l’idée d’utiliser des robots.txt ou des balises META peut toujours sembler écrasante.
Mais, si vous avez déjà regardé de façon excessive « Stranger Things », bienvenue dans le futur.
Espérons que ce guide fournira plus d’informations sur les bases de robots.txt et des balises META. Si vous espériez que des robots volent dans des avions à réaction et voyagent dans le temps après avoir lu cet article, je suis désolé.
Crédits d’image
Image vedette: Paulo Bobita